Study BenchIP, a Benchmark for AI Hardware
Benchmark对于评估不同系统优劣,以及系统的优化(包括软件和硬件的优化)都大有裨益。当前存在的问题:
- 当前的benchmark对于智能芯片来说,缺点是non-diversity和nonrepresentativeness,导致不可用
- 缺少一套标准的benchmarking methodology
从这两个角度出发,提出了BenchIP,一个benchmark套件以及benchmark的思路。BenchIP主要分为两块:
- microbenchmark,单层网络下的典型操作,主要用于评估系统瓶颈以及系统可优化点
- macrobenchmark,使用最领先的网络,测试不同平台在实际系统下的性能
BenchIP被设计成可用来评估不同的平台,CPU,GPUs,和其他加速器,这也是我们自己定义或者借鉴benchmark需要考虑的问题。
1. 引言
1.1 以前的Benchmark
有两种Benchmark存在:collective benchmark(很多应用的集合)、personalized benchmark(评测不同的智能芯片)。
BenchNN,来源于PARSEC,证明了神经网络的潜力,但有如下限制:
- 只提供了5个神经网络应用,数量少
- 实现的是简单的多层感知机,未覆盖领先的其他技术,例如反向传播
- 没有实现其他benchmark中的反映多样性的应用,比如ferret、streamcluster等
DeepBench,测试不同平台上基础操作的性能,比如矩阵乘、卷积、循环层、全归纳(all-reduce),没有覆盖神经网络全栈中的高层行为。而某些高层行为,例如Faster-RCNN不能用DeepBench中这些有限的操作来反映。
Fathon,由8个典型的深度学习workload组成,但有如下不足:
- diversity不足,只包含一些通用层,卷积,全互联,但是缺少一些重要层,比如Deconv,Unpooling,Batch normalization
- 架构相关了,不能评估定制化硬件架构
- 不能评估细粒度的性能和效率,这对智能芯片特别是定制化硬件非常重要
上面提到的都是一些collective benchmark,而一些personalized benchmark则更缺乏代表性和多样性。
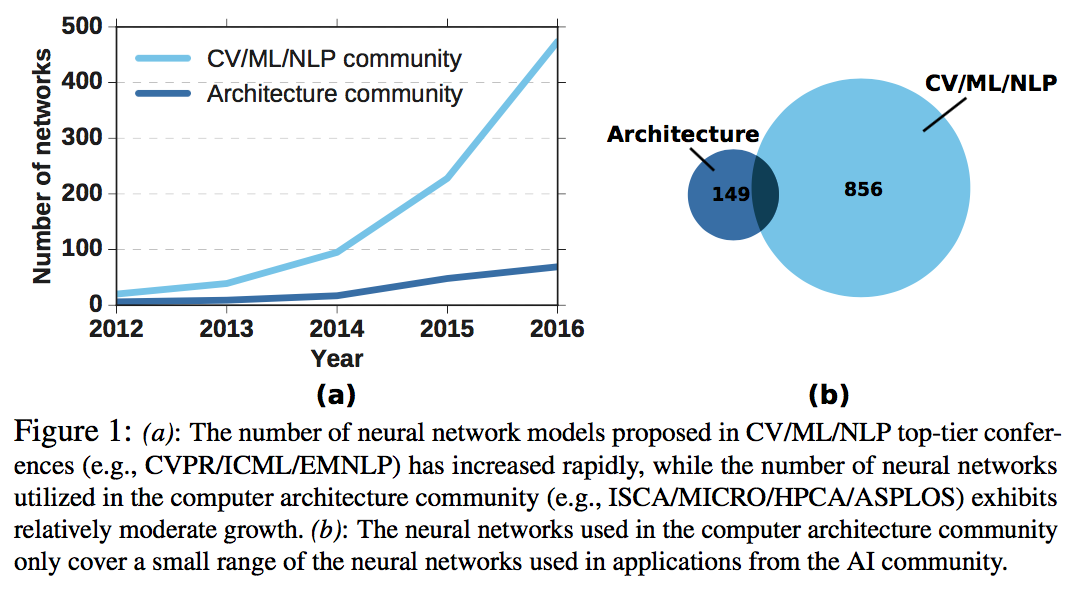
左图说明了传统的计算机架构领域根本没有覆盖足够的神经网络模型,右图说明了在传统计算机架构领域有30%~50%的benchmark在AI领域不可用。
1.2 Benchmarking方法论
benchmark除了说明测试什么,还要确定怎么测试,也就是需要一套方法论作为指导。主要有两种方法,一种类似chaotic,基于一套餐现代的计算机系统的软硬件栈,这对于评估新硬件不利,因为他的软件栈可能根本不存在。而还有一些Benchmark则去掉软件栈,直接在RTL层评估,但这又反映应用实际情况。因此,Benchmark需要定义好评估的Framework,指标metrics,具体方法。
智能芯片一些独有的特性也增加了方法论的难度,比如精度。AI芯片的精度可以在性能、功耗、芯片面积几个参数间取舍,可以牺牲少量的精度保证性能或者能耗更优,但过分牺牲则不可比较了。因此,Benchmark中需要定义好这些AI芯片专有的特性。
1.3 BenchIP简介
Benchmark suit主要包含两块:
- microbenchmark,12个代表性的单层任务,比如convolutin, pooling, activation
- macrobenchmark,11个常用的全神经网络,比如AlexNet,VGG,Faster-RCNN
Benchmarking methodology,从三点上来设计:
- 置信度,以一个工业级的软件栈,包含高层编程模型,库,设备驱动全栈操作
- 可移植,通过一个中间层的高性能库,对于一个新的架构按照标准接口编译即可
- 公平性,引入了精度这个指标
因此,该Benchmark做了如下几个方面的事情:
- 包含micro和macro两个纬度的benchmark,可以用来评估智能芯片的精度、性能、功耗
- 通过大量分析,验证了本benchmark具有多样性和代表性
- 提出了一个包含工业级软件栈的benchmark方法,保证置信度,可移植,公平性
- 评估大量芯片,包括CPU、GPU和加速芯片
2. The Benchmark Suit
Benchmark的设计需要从两个视角考虑:
- 应用的视角,需要覆盖了绝大多数场景,并且又没有多少冗余测试相似的特征
- 架构的视角,需要能反应底层架构的瓶颈,以及未来趋势
因此BenchIP也从两个纬度来设计case,micro是从底层设计了很多单层操作,同时配套多种配置,macro则更多从整个神经网络,用于评估端到端的智能任务,在这类任务中数据在layers之间的移动是很关键的。
2.1 Microbenchmarks
微架构的评测对于优化和学术研究来说都非常重要和常见,比如测试内存带宽的STREAM,可以测试MPI同步开销,循环调度,队列操作的OpenMP microbenchmark。对于深度学习来说,其微操作就是单层网络。和DeepBench不同,BenchIP没有选择非常基本的操作,因为这些操作不能评估数据移动的效率,而是选择如下图的操作,这些操作的选取有三个原则:
- 很常见,大量应用在当前的神经网络中
- 有不同的计算、访存、控制操作比例
- 对未来设计有很大影响(是显著影响性能的操作)
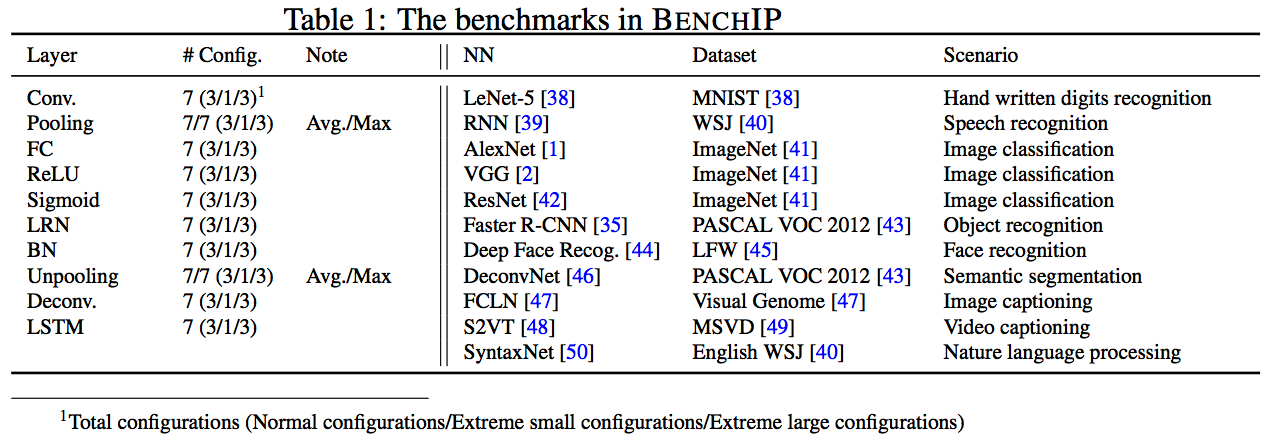
同时通过论文等手段,确定各种layer被网络使用的频率,
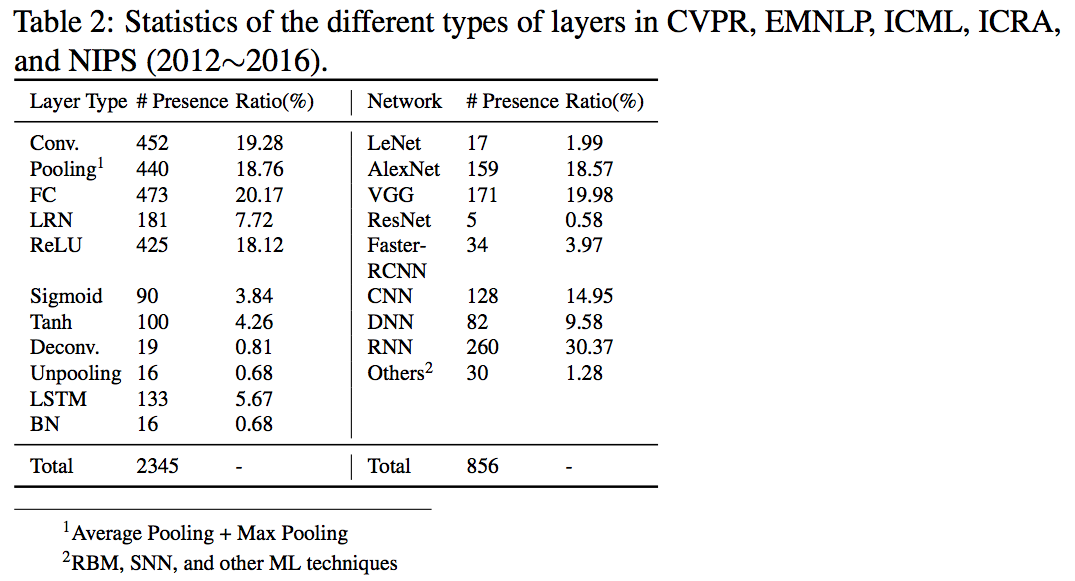
2.2 Macrobenchmark
Macrobenchmark就是从实际的应用中抽取出workload,SPECCPU、PARSEC等spec都是这样的形式。而从神经网络来说,BenchIP选取了11个网络,考虑如下因素:
- 相比微架构的benchmark,端到端的任务更多是使用完整网络的,例如语音识别
- 从底层单独的layer类推高层网络是非常低效的,因为有很多诸如数据交互的因素影响两个网络间的性能和功耗,处理起来非常复杂
- microbenchmark不能用于层中间的优化
具体的case,以及在实际出出现的频率,如上面的图。
- LeNet-5,代表手写笔记识别
- RNN,代表语音识别
- AlexNet,VGG,ResNet,代表图像处理
- Faster R-CNN,代表目标检测
- Deep face recognition,代表人脸识别
- DeconvNet,代表语义分割(切词?)
- FCLN,代表图片理解
- S2VT,代表视频理解
- SyntaxNet,代表自然语言处理
2.3 Benchmark analysis
主要是研究microbenchmark,因为macrobenchmark都是由microbenchmark组成的,但也会讨论macrobenchmark的相似性。
主要是case的多样性,主要是从两个方面来看:
- 利用聚类的方法,看不同的microbenchmark是不是聚类都很远
- 利用heatmap来看,各个case间是不是关联很小
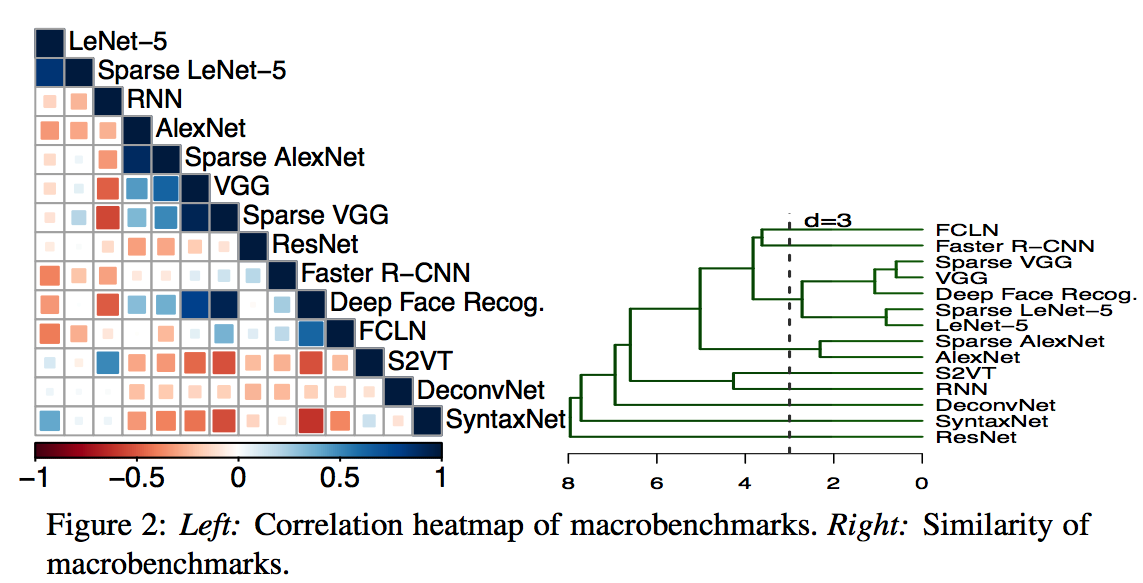
上面方法中用的特征主要分位三类,memory,computation,control。

对benchmark的分析分为两个纬度:inter-layer和intra-layer。其中inter-layer也就是case间的,就是上面分析的。而intra-layer则是评估每个case本身,用的是上图中列的特征,以及相应的7个配置来评估的。
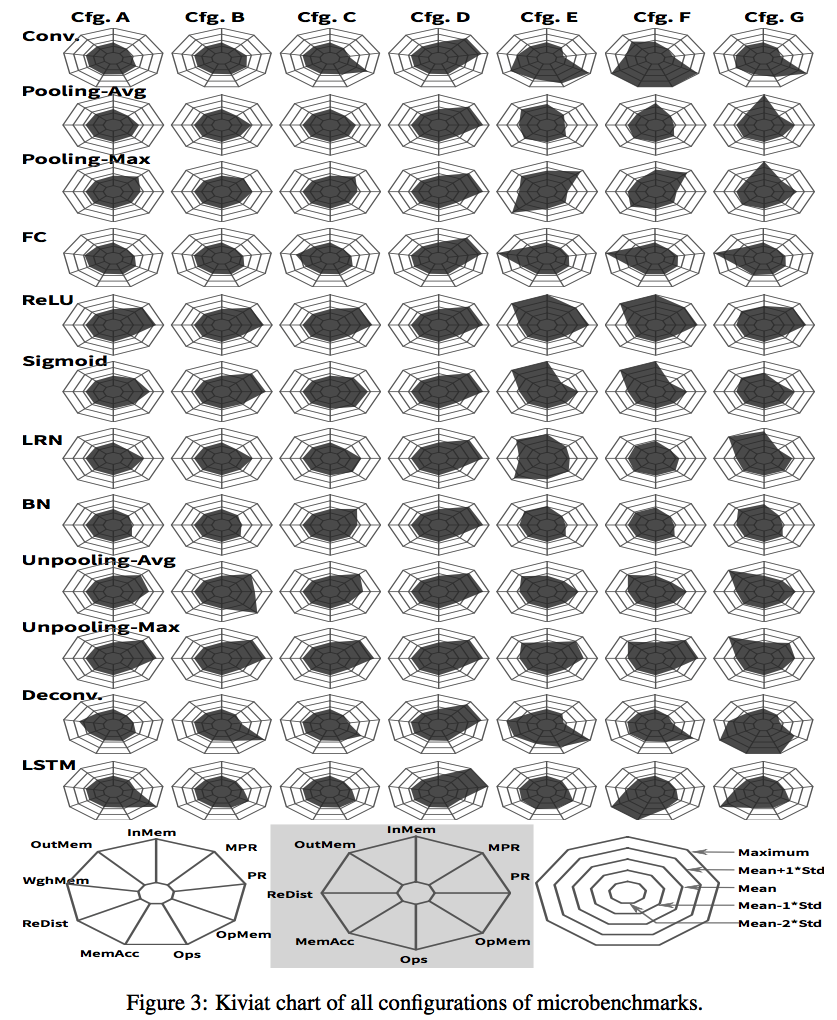
一些结论:
- 大多数配置的reuse distance都小于10,因此本地的内存可以设计成10*element_size,这样可以减少off-chip访存
- Cfg.F of Conv配置,reuse distance超过了10的6次方,这意味着on-chip的memory需要10MB,这在成本上是不可能的,而像DaDianNao会使用eDRAM或者3D-stacked DRAM在on-chip的SRAM和off-chip的延迟之间做平衡 而对于Conv和FC来说,其reuse distance在不同配置下变化非常大,因此对于这种Layer需要有定制的内存架构
- 从计算的角度来说,大多数Ops都小于10的8次方,但是有少量case会达到10的10次方;并且通过memory access占比可以将任务简单区分为compute敏感或者内存敏感
- 从控制的角度来说,一般情况下小配置的MPR要大,因为他们的计算要少 从底层角度来说,需要评估benchmark是否能测试微架构的极限。而上面配置中的极限配置都对每个部件或者因素有很大的压力,比如reuse distance很是不一样,会增加L2 cache miss很多倍;操作的Ops在极限配置下也是显著的多。另外一个纬度就是考虑未来趋势,主要有两个:
- 在更多通用问题上,会有更多的算法和网络结构实现高精度的解决方案。BenchIP在计算、访存、控制上都非常多样,应该能覆盖到这个趋势,同时在保持高频率更新,更不会落后于时代
- 模型会为了保证performance/energy的效率,牺牲少量的精度,比如稀疏矩阵、低精度模型。BenchIP上提供了稀疏矩阵和低精度的支持,所以应该也能覆盖这个趋势
3. Benchmarking Methodology
主要框架如下图:
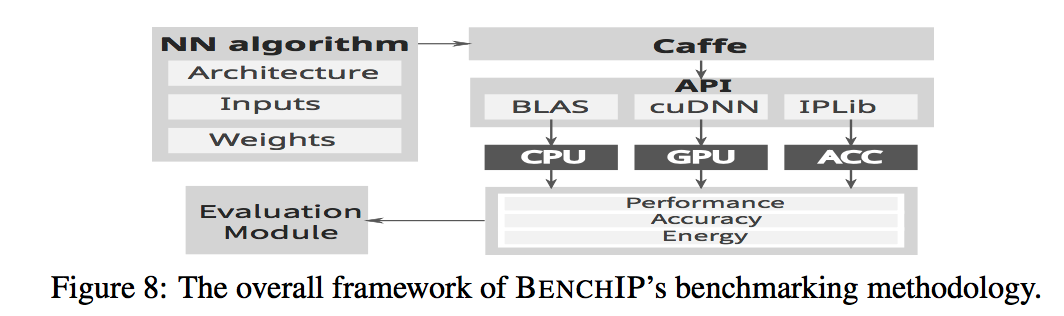
Benchmark Specification,需要为caffe输入配置相关的信息,主要包括:
- 配置文件,描述网络架构,每个layer的参数,各层layer之间的连接,caffe支持的.prototxt
- 输入数据,数据层和测试层是独立的?
- 学习的参数,指定各layer存储的权重,.caffemodel
- 参考输出,用来评估计算的精度;如果是microbenchmark,将参考输出和计算输出按照MSE来计算准确度,而对于macrobenchmark,可以使用原始嗯metrics?
Library Interface,这是为了屏蔽底层硬件的一层,CPU采用了BLAS,GPU采用了cuDNN。对于一个新的硬件来说,仅仅需要实现一些预先定义好的C++接口即可。
Evaluation Metrics,主要是performance、enery、area和accuracy四个。对于CPU采用PAPI接口,GPU采用nvsim接口采集这些信息。对于一个新的硬件来说,如果是模拟器上,应该输出这些信息。在macro纬度,还引入了efficiency的一系列参数,operations per Joule作为能耗效率,operations per second作为计算效率,accuracy affected by area savings作为芯片效率。用这些指标即可用于问题的针对,也可以作为后续优化的一个指标。
4. Benchmarking with BenchIP
测试了8款不同类型的处理器,包括CPU、GPU、ACC,评估指标包括GOPJ,GOPS,performace,enery,而没有关注area和accuracy,因为不同的硬件这两个指标相差不大。观察到的一些现象:
- 嵌入式CPU在silicon area的使用率上要更好,甚至好于总所周知的能耗效率
- GPU是更好的计算能耗效率,并且仍然在提升,desktop的GPU有最好的tradeoff
- 定制加速器在各种指标上都表现较好,同时在性能效率上的提升没有能耗效率的提升显著,并且有更好的silicon area使用率
- 因为稀疏化,ACC-1比ACC-2效率更高
基于micro纬度,
- desktop的CPU具有最好的性能
- 嵌入式GPU在数据量小的时候,比CPU好不了多少,因为不能充分发挥计算能力
- ACC-2具有最好的性能,并且ACC-1和ACC-2在大配置下比正常配置下具有更好的性能
- ACC-1在复杂和不规则的网络上ResNet、DeconvNet比不上CPU和GPU,但是其他模型都要好,因为ACC-1就是为CNN和DNN设计的
- ACC-1在小网络的时候效率非常高;但在重的负载下,比不过server上的GPU 另外没有一个比较好的Overall Score直接判断各个架构的好坏,一个可能的定义就是整体效率,但这也是一个用户定义的行为。
!!!!!总结
BenchIP更多还是从一些经验出发,提取除了常见的case作为benchmark,而对于profile的关联很少,比如常见的configure怎么定义出来,软件可能优化点等 更多为了提出一个通用的benchmark,无论是CPU,还是GPU,还是定制的加速器,因此定义的架构无关的,而对于架构相关的则没那么深入,比如正确比较两款GPU的极限吞吐,以及模型具体瓶颈,进而进一步优化点 类似第二点,即使架构无关,一些供优化的评断指标,过于上层;计算、存储、控制,而对于存储上具体可优化点是哪