Domain Specific Architecture:Introduction
1. Introduction
硬件功耗极限没有像性能那样增长,因此当前为了提升硬件极限,则需要优化energe per operation。
如果按照以往的技术,更多核心可能能获得10%左右的性能的提升,但是要想性能进一步提升,则需要将arithmetic operations per instruction提升百倍,这就更需要专用处理器。
以后的系统,会有通用的处理来处理一些例如操作系统的通用任务,而专用处理器则完成他擅长的工作,比如某种计算。

以前一些架构的特性,比如cache,out-of-order等能很好等满足通用计算等需求,但是对于一些特殊等领域则会在silicon和energe上都有浪费,反而不使用这些通用特性能获得更大优势。比如vedio领域,数据往往很大,也基本上不重用,cache则完全是浪费。
DSA往往只针对系统的某个subset,而不是考虑支撑其整个系统。对于DSA研究来说,最大的两个问题是:
- 怎样平衡成本,因为NRE(nonrecur- ring engineering)和软件支持的成本是很高的,如果需求量小,得不偿失。FPGA是一个选择。
- 怎样将算法移植到硬件上,传统的C++开发和编译等组件不会发挥多少作用
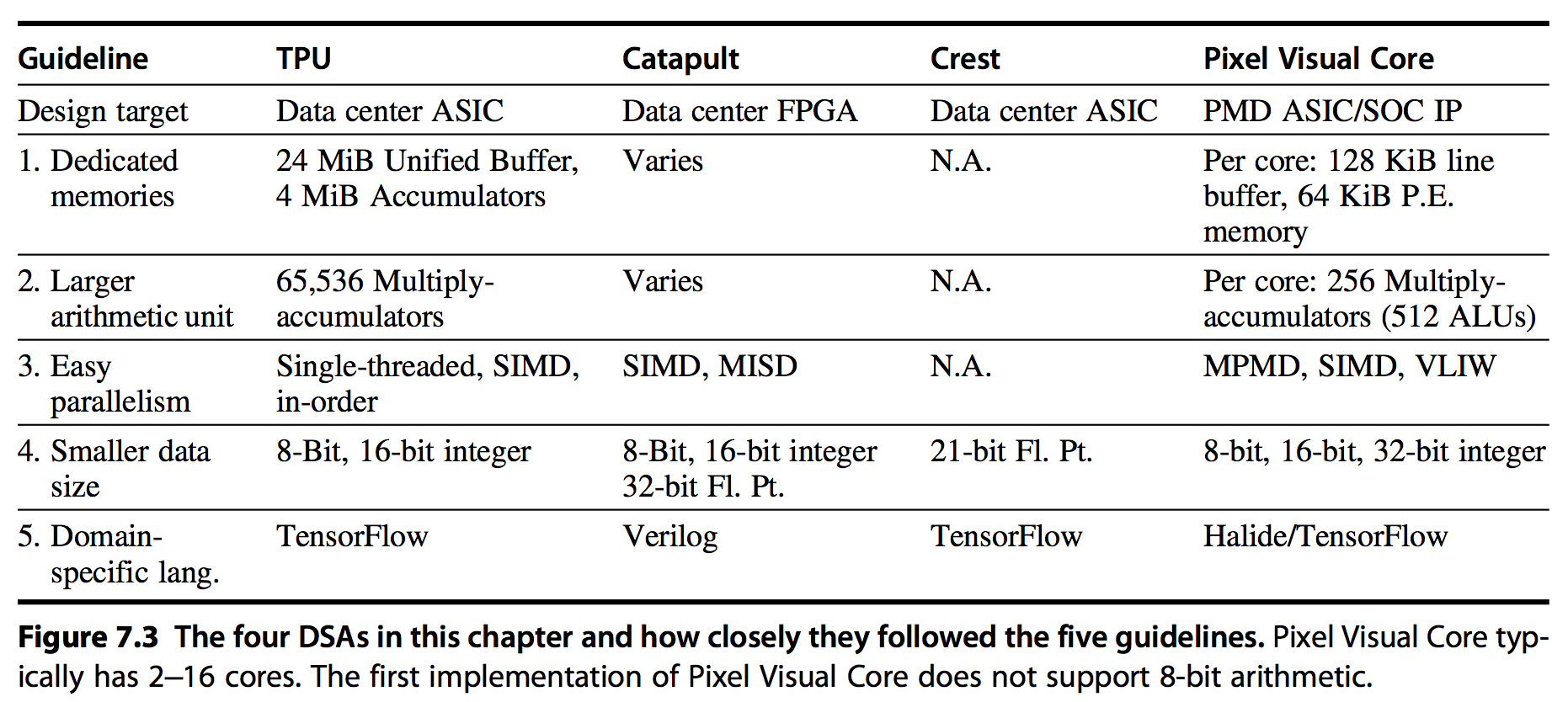
2. Guidelines for DSA
下述Guidelines有如下好处:
- 帮助增加area和energe等效率
- 尽量降低DSA的NRE成本
- 相比传统架构的优化,能更好的满足面向用户的latency需求
基于对处理问题的数据和执行的操作更理解,提出了如下5点Guidelines:
- 用专门设计的内存减少数据搬移的距离:a two-way set associative cache uses 2.5 times as much energy as an equivalent software-controlled scratchpad memory
- 将资源倾向更多的计算和更大的内存,而不是传统先进微架构为了满足摩尔定律的优化手段(out-of-order execu- tion, multithreading, multiprocessing, prefetching, address coalescing, etc)
- 使用符合domain的更简单的并行手段:For example, with respect to data-level parallelism, if SIMD works in the domain, it’s certainly easier for the programmer and the compiler writer than MIMD. Simi- larly, if VLIW can express the instruction-level parallelism for the domain, the design can be smaller and more energy-efficient than out-of-order execution.
- 减少data size,够用即可,可以提高内存利用率,也可以在相同chip area放更多计算units
- 使用domain-specifc的语言
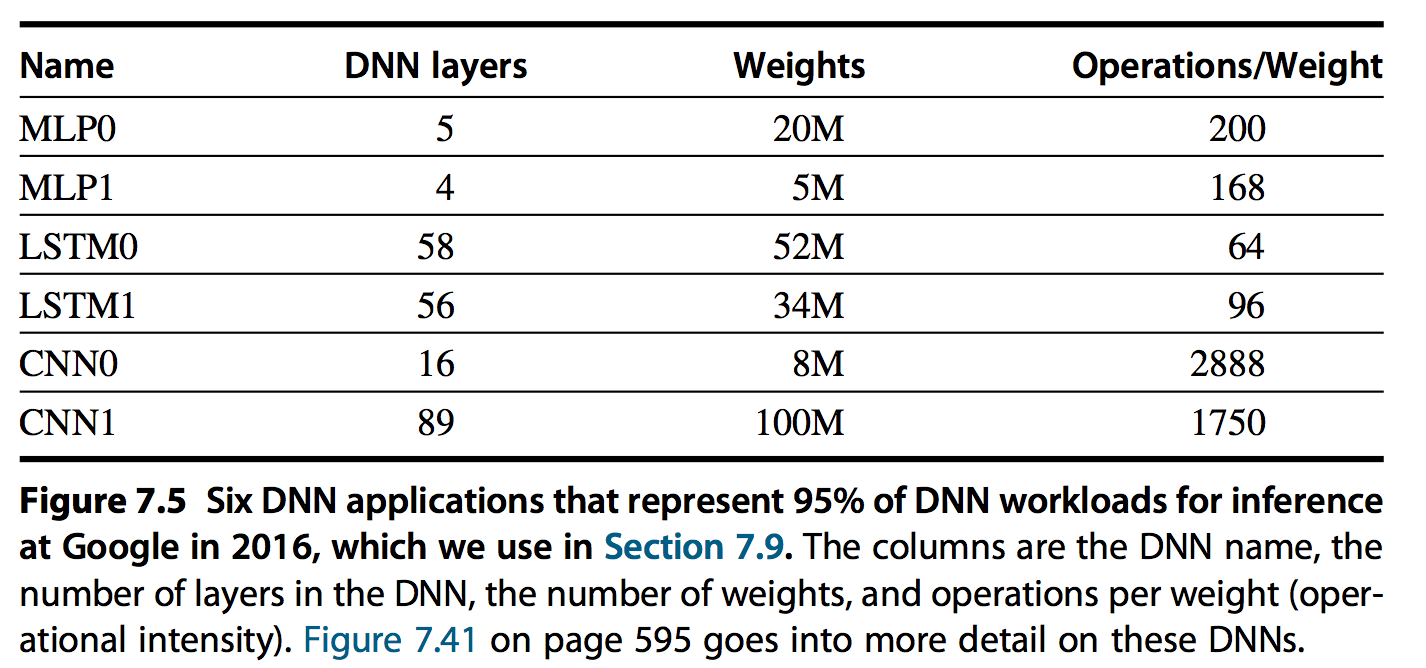
3. DNN简介
最常见的DNN信息如下:
3.1 MLPs
MLPs是最原始的DNN,他的每一层都是上一层的输出和一组权重值矩阵相乘的结构。由于每个feature值都以来上一层的所有输出,所以这种方式称为全互联(fully connected)的方式。
它的主要结构图如下:
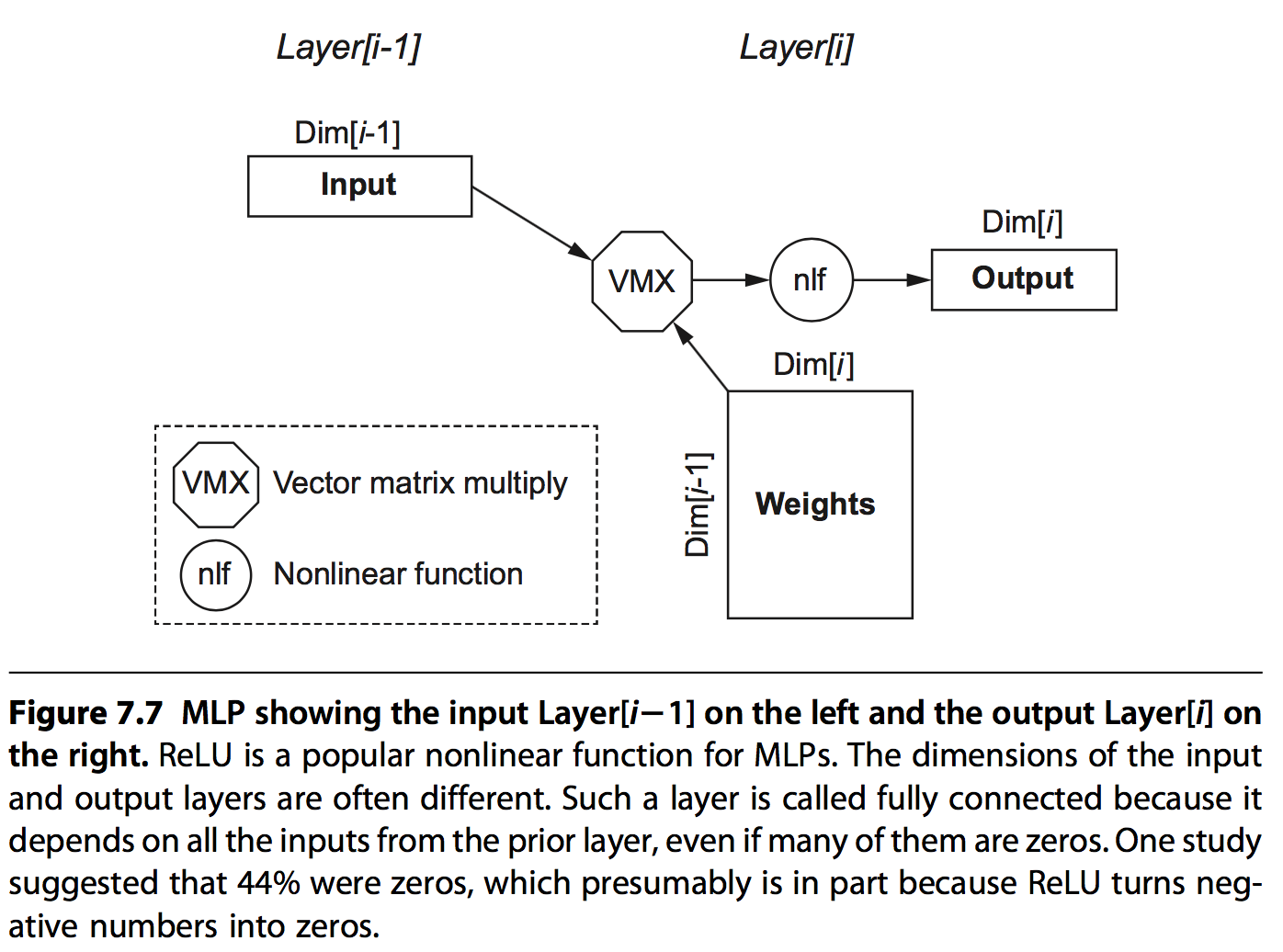
通过此结构,可以很容易的计算出每层网络的一些基本信息:
- Dim[i]: Dimension of the output vector, which is the number of neurons
- Dim[i 1]: Dimension of the input vector
- Number of weights: Dim[i 1] Dim[i]
- Operations: 2 Number of weights
- Operations/Weight: 2
Operations/Weight只有2,也就是operation intensity 只有2,根据roofline模型可知,此模型很难有很高的performance。
3.2 Convolutional Neural Network
CNN是另外一种形式,每个feature值是前一层输出的部分值与权重乘加的结果,基于两点:
- 一些场景下(比如图片),相邻的数据往往具有相关性
- 每一层layer都会提高对象(比如图片)的抽象级别,从线到图形到鼻子到类别等
其具体结构如下:
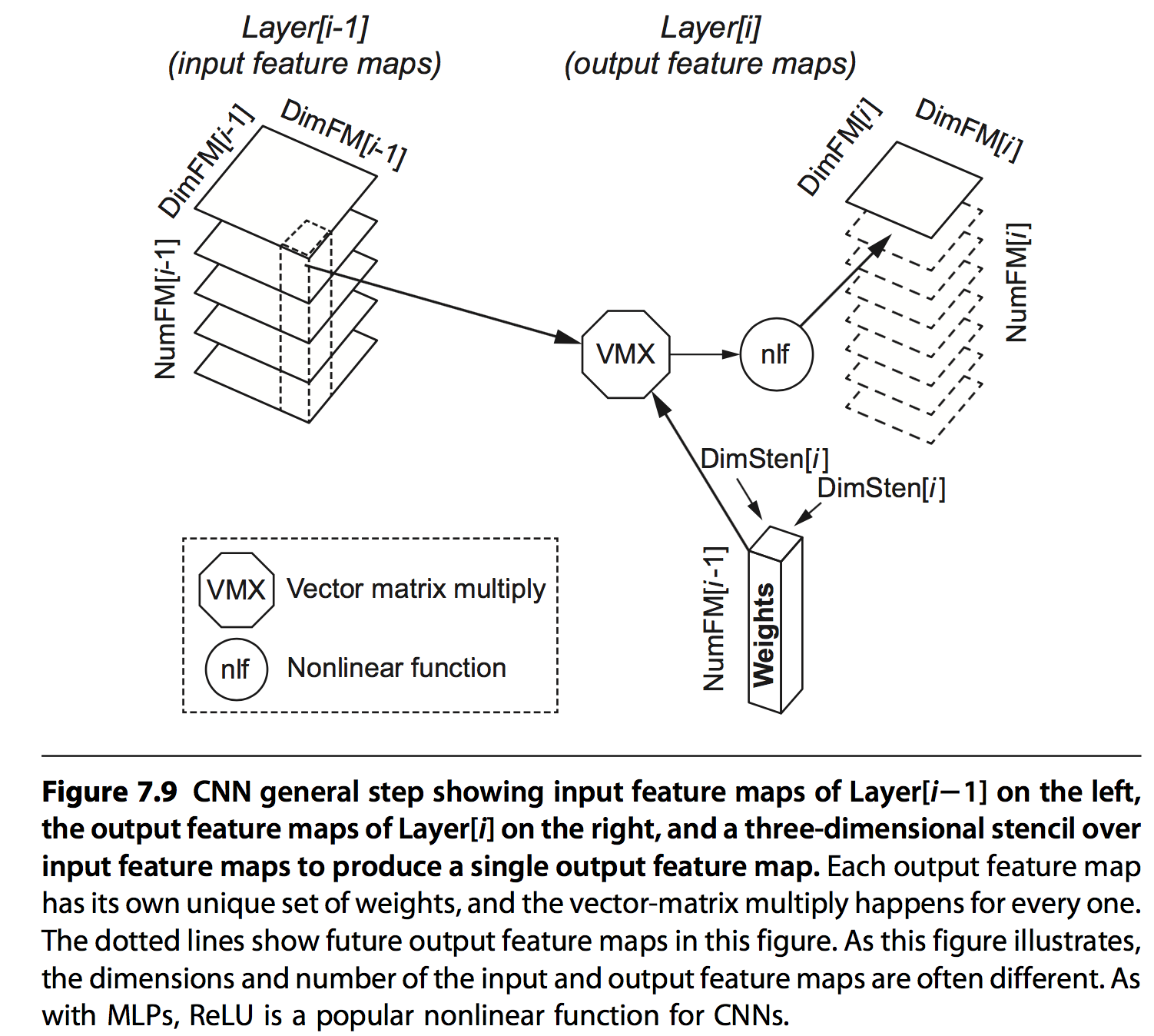
每层网络的基本信息:


3.3 Recurrent Neural Network
RNN在一些上下文关联的场景特别有用,比如语音识别。使用的方法就是给序列化输入建模时增加状态,也就是说模型会记录之前的一些信息。
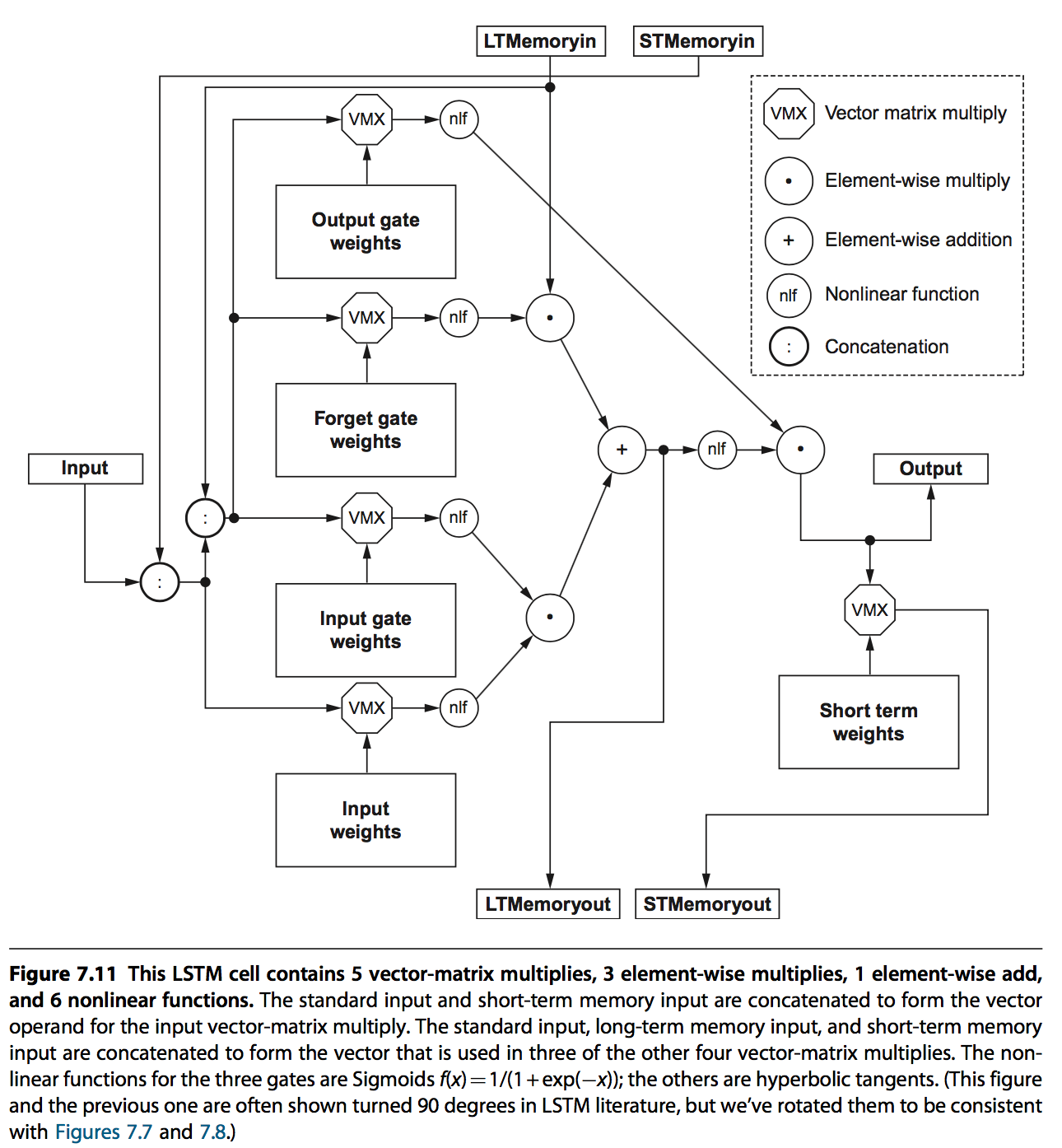
LSTM是当前最流行的算法,通过long-term memory记录长期信息,short-term memory记录上一次的信息,并通过相应的weights以及gates来作用到输出。
weights是用来做矩阵求和的,gates则是用来确定哪些信息能作用到输出或者memory中:
- input gates,output gates,用来筛选输入输出;
- forget gates,用来筛选哪些作用于long-term memory

每一个cell的结构如下:
LSTM相关的一些信息如下:
