Domain Specific Architecture:TPU
1. 简介
- 用于Inference
- 有65536(256*256)8bit ALU Matrix Multiply Unit
- 大内存
2. 架构
先摆出基本架构图:
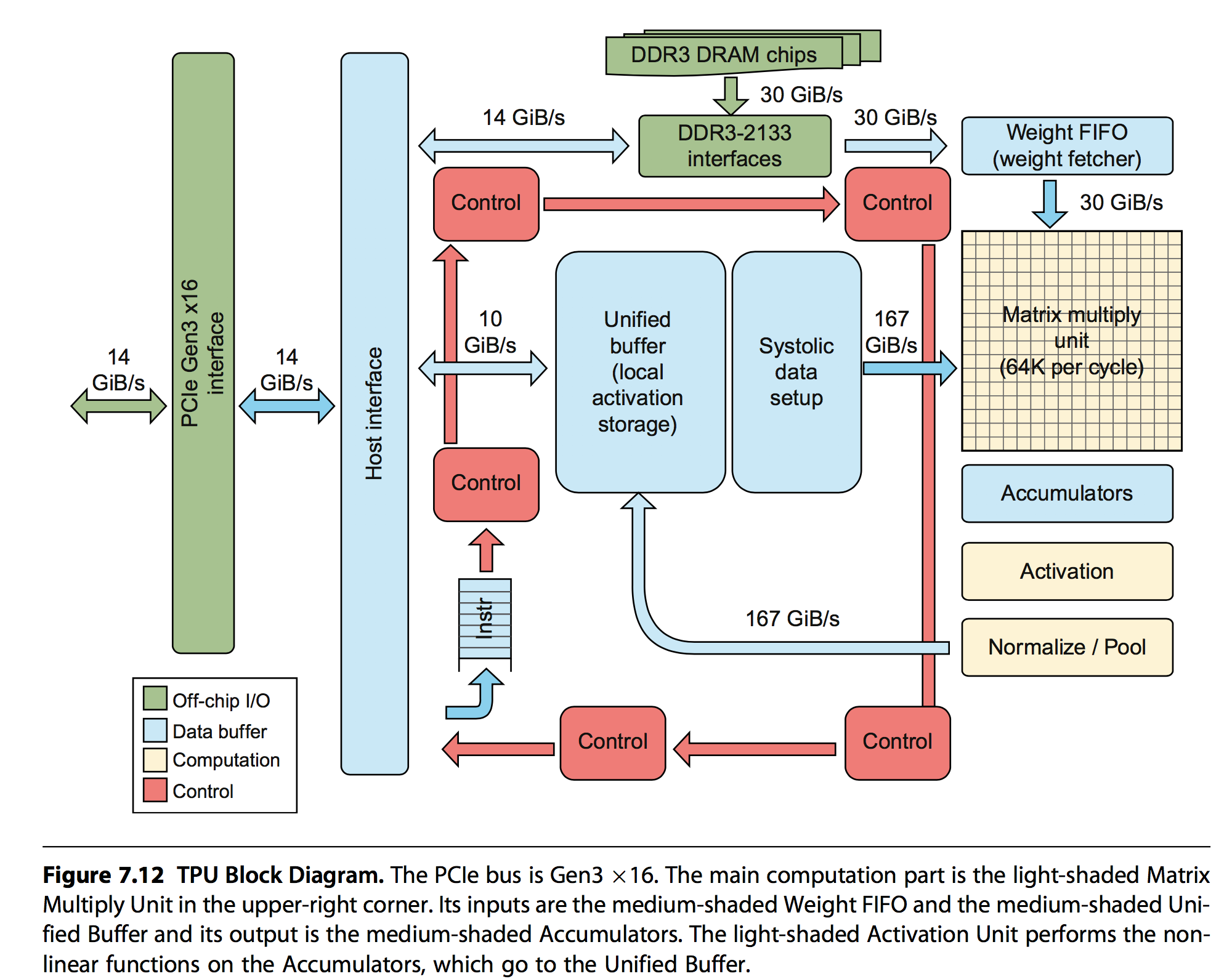
几个主要组成部分是:
- Matrix Multiply Unit:执行8bit的矩阵乘加
- Accumulators:存储矩阵乘加输出的中间结果
- Activation:执行非线性激活函数
- Weight FIFO:从外部的Weight Memory中缓存权重信息
- Unified Buffer:从主机内存中读取中间结果
3. 主要操作
结合架构中的主要部件,主要有如下指令操作:
- Read_Host_Memory:从主机读取输入信息到Unified Buffer中
- Read_Weight:从Weight Memory中读取权重信息到Weight FIFO中
- MatrixMultiply/Convole:将Unified Buffer中的信息与Weight FIFO中的信息执行指定操作,结果存储到Accumulators中
- Activate:执行非线性激活函数,并将结果写回到Unified Buffer中
- Write_Host_Memory:将结果写回到主机内存中
TPU中的指令有12 bytes,其中3个bytes是Unified Buffer地址,2个byte是Acumulators地址,4个byte是length,剩下的是opcode和flags。
TPU的设计哲学就是保持MatrixMultiply处于繁忙的状态,最大化的发挥计算能力。和流水线的思路一致,将上述的操作都用专门的硬件来执行,同时在执行MatrixMultiply操作的时候,也并行的激发其他硬件的工作,这样就会将部分时间overlap掉,从而降低计算需要等待的时间。为了进一步提高并发行,Read_Weight的操作也会解耦,由于是专门硬件在处理,所以该操作可以在发送address,但是weigths从Memory中读取到之前就返回,MatrixMultiply通过专门的not-ready信号来判断数据是否准备好。
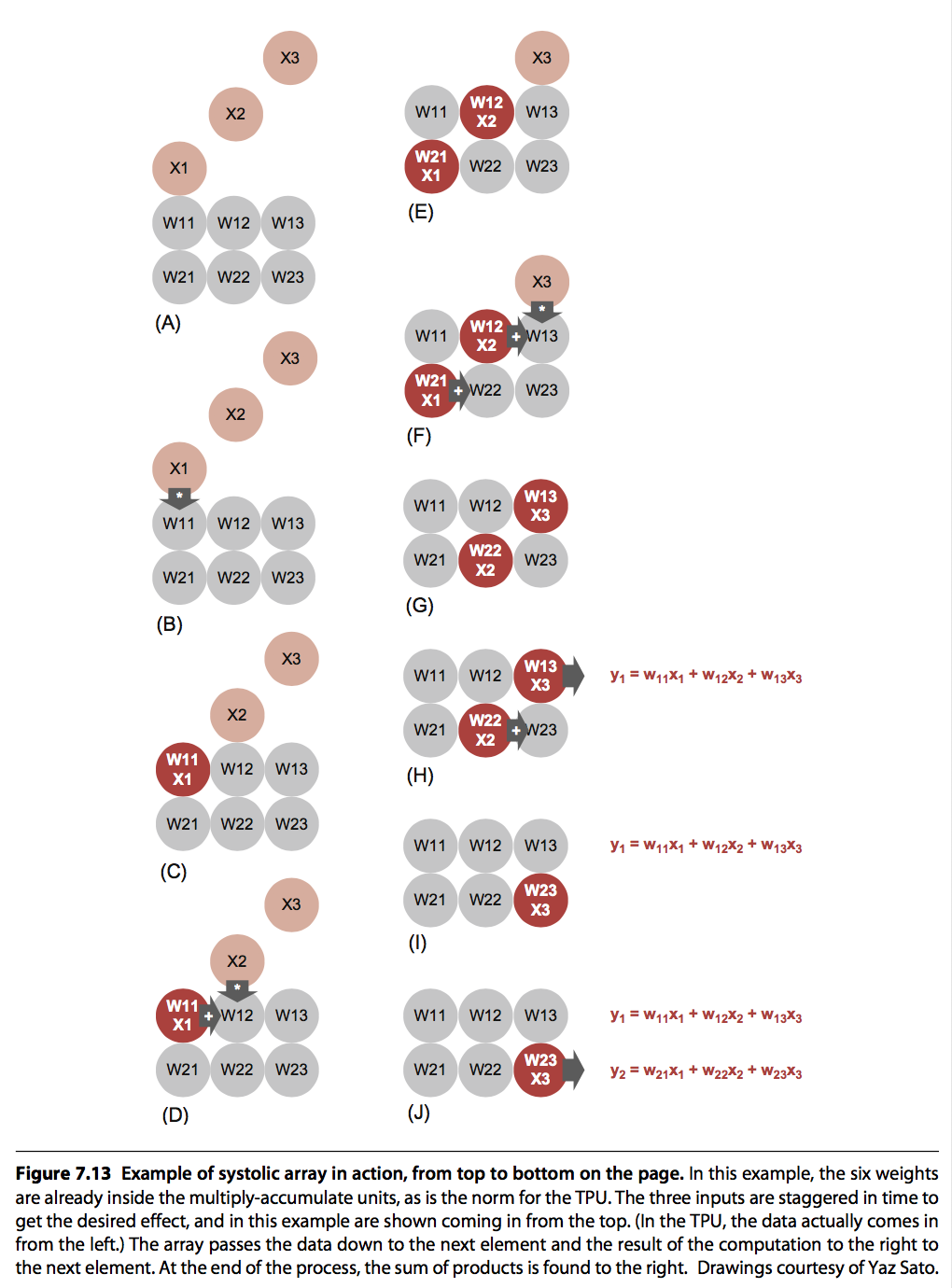
TPU中MatrixMultply应用的一个关键技术是:脉动阵列。它是结合矩阵运算这种特殊的场景而设计的专有硬件计算架构。脉动阵列是一个二纬计算单元的阵列(当然也存在更高纬度的),阵列中的每个cell利用相邻单元传递过来的参数和中间结果计算这一个cell的中间结果,数据依次传递,而不是重新从内存中读取,犹如波浪一般,脉动阵列因此得名。这种结构只需要读取一次内存数据,写入一次最终的结构到内存,因此计算非常高效。
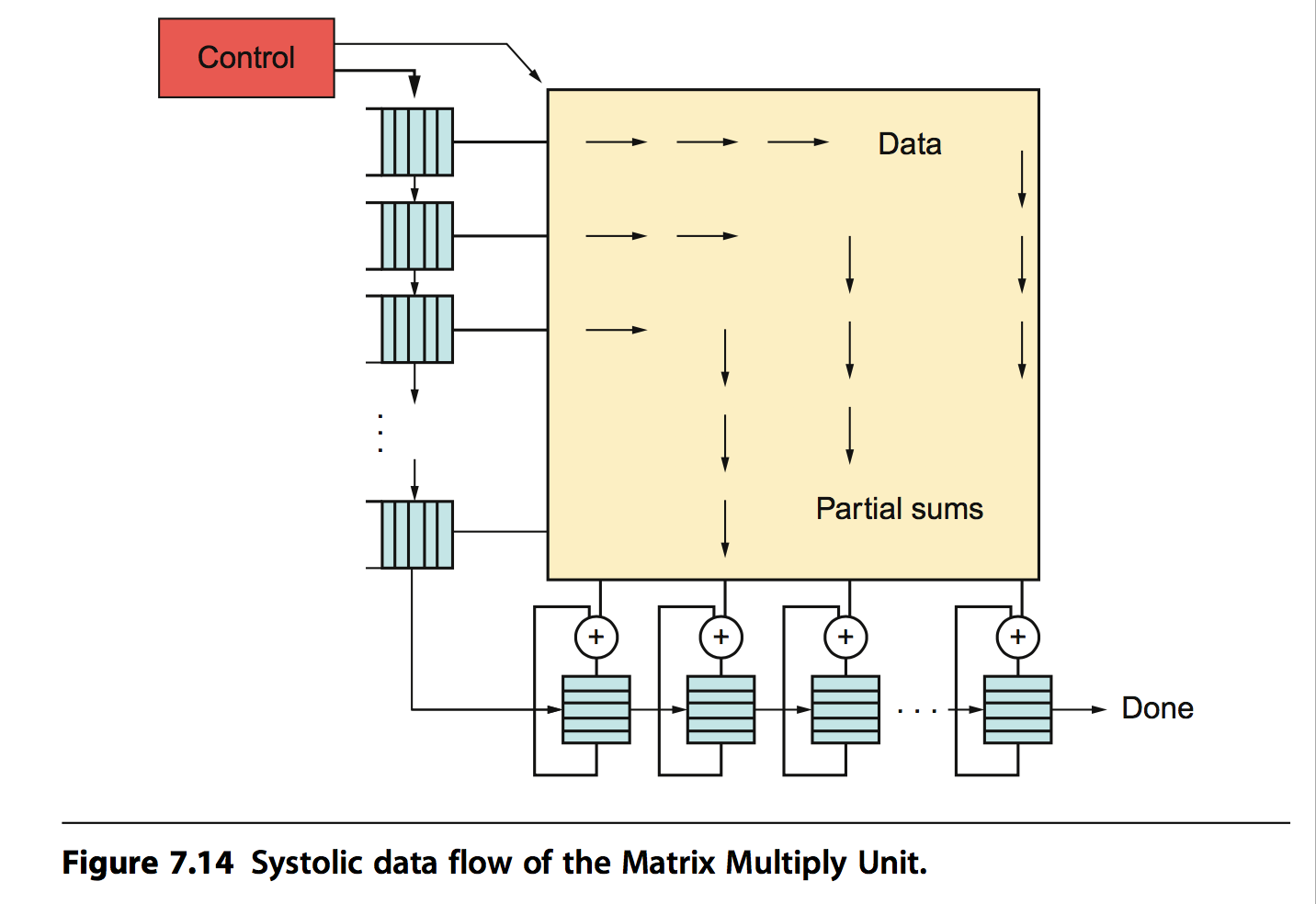
TPU中脉动阵列的实现如下图所示:
4. 实现
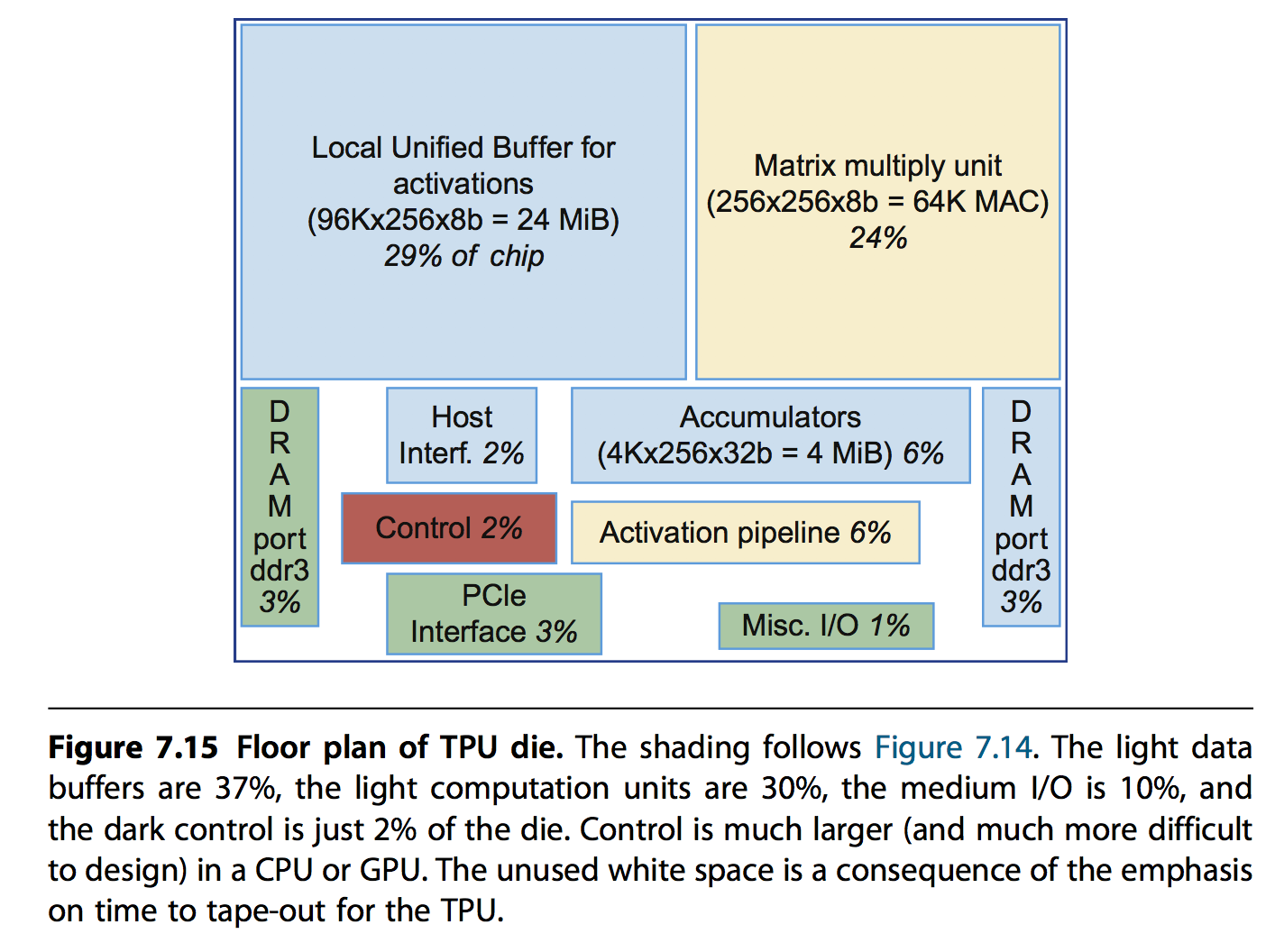
硬件实现的一些基础信息如下:
- 28nm,700MHz,芯片面积应该小于Intel Hashwell CPU(662mm*mm)
- Unified Buffer,24MiB,占了约芯片面积三分之一的空间
- 控制逻辑只占有2%的空间 也就是说计算密度非常大。框图如下:
配套软件上的实现信息如下:
- 基于TensorFlow,和GPU接口保持兼容
- Kernel Driver,用来管理内存和中断,非常稳定
- User Space Driver,包括模型编译,格式化数据到TPU的order,控制具体执行逻辑
- 每次计算一个layer,尽量hidder非关键操作
一些性能评估模型表明,TPU的几个关键组件影响性能的程度:
- Memory,影响非常明显,因此使用更快的内存很有必要
- Clock,提升效果不明显,这是因为很多时间都是在等待内存
- Matrix大小,反而有副作用,这是因为矩阵更大,一次计算时间会成幂数增长,比如一个600600的计算,在256256的MatrixMultiply中需要9个step,每次2us,总计18us,而在512512下,虽然只需要4个step,每次8us(22*2),但是总时间会变为32us
5. 评估
待补充