现在大家都是在一些Framework上实现自己的神经网络模型,借助Framework抽象的概念,接口来方便的完成模型的训练和推理工作。 [TODO]
...
Glow, 针对神经网络的图编译技术 发布于 May 13, 2018
现在大家都是在一些Framework上实现自己的神经网络模型,借助Framework抽象的概念,接口来方便的完成模型的训练和推理工作。 [TODO]
...
Domain Specific Architecture:Catapult 发布于 April 23, 2018
1. 简介
微软出于如下目的设计了Catapult:
- 便于部署,不增加实现和调度的复杂度,即使它和DSA的概念有冲突
- 可扩展性好,有些应用需要一个accelerator所有资源
- 功耗效率高
- 没有单点故障的问题
- 满足当前servers上空间和功耗的限制
- 不能影响数据中心网络性能和可靠性
- 需要改善server的cost-performance
2. 硬件规格
主要参数如下:
- 功耗:25w
- 制程:28nm
- Flash:32MiB
- OffChipMemory:8GiB
- ALU:3926 8bit
- OnChipMemory:5MiB
- 网络:20Gbit/s
样式图如下:
数据中心的半个rack中有48个服务器,每台服务器插有一块catapult。如前面介绍为了不影响网络环境,有专门的低延迟的20Gbit/s的网络连接这48个catapult,组成一个二维的6*8的环形网络。
为了避免单点故障,在catapult的网络中,支持一个FPGA失败的时候,重新配置整个环境。并且catapult主板对FPGA外的所有内存支持SECDED的保护,这需要这个方案在数据中心中大规模部署。
由于使用了大量内存,catapult会比ASIC跟容易遇到single-event upset(SEUs)的问题。因此,FPGA支持检查并修正SEUs的功能,同时周期性的清洗(scubbing)FPGA的配置状态以降低SEUs的概率。
3. 软件支持
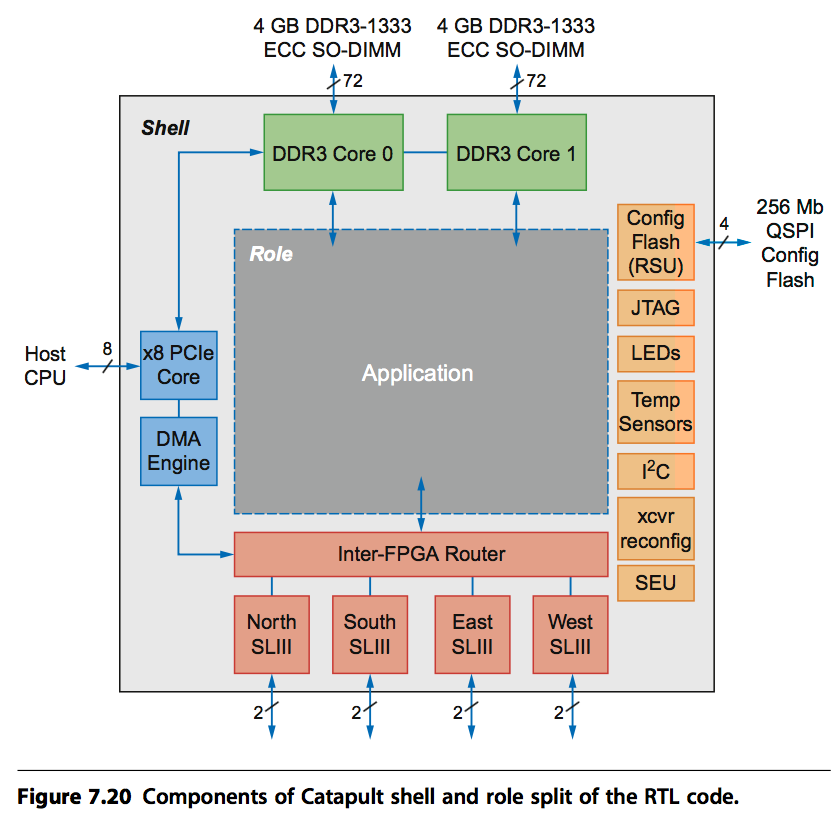
众所周知,FPGA最大的问题就在可编程性,它需要专门的语言(RTL)与器件才能实现。为了让catapult支持更多的应用,RTL分为shell和role两层。其中shell是基础层,用来实现一些大家都需要的功能,比如数据清洗,CPU-to-FPGA通信,FPGA-to-FPGA通信,数据迁移,重配置,心跳检测等等。而role则是每个应用自己特殊的功能。
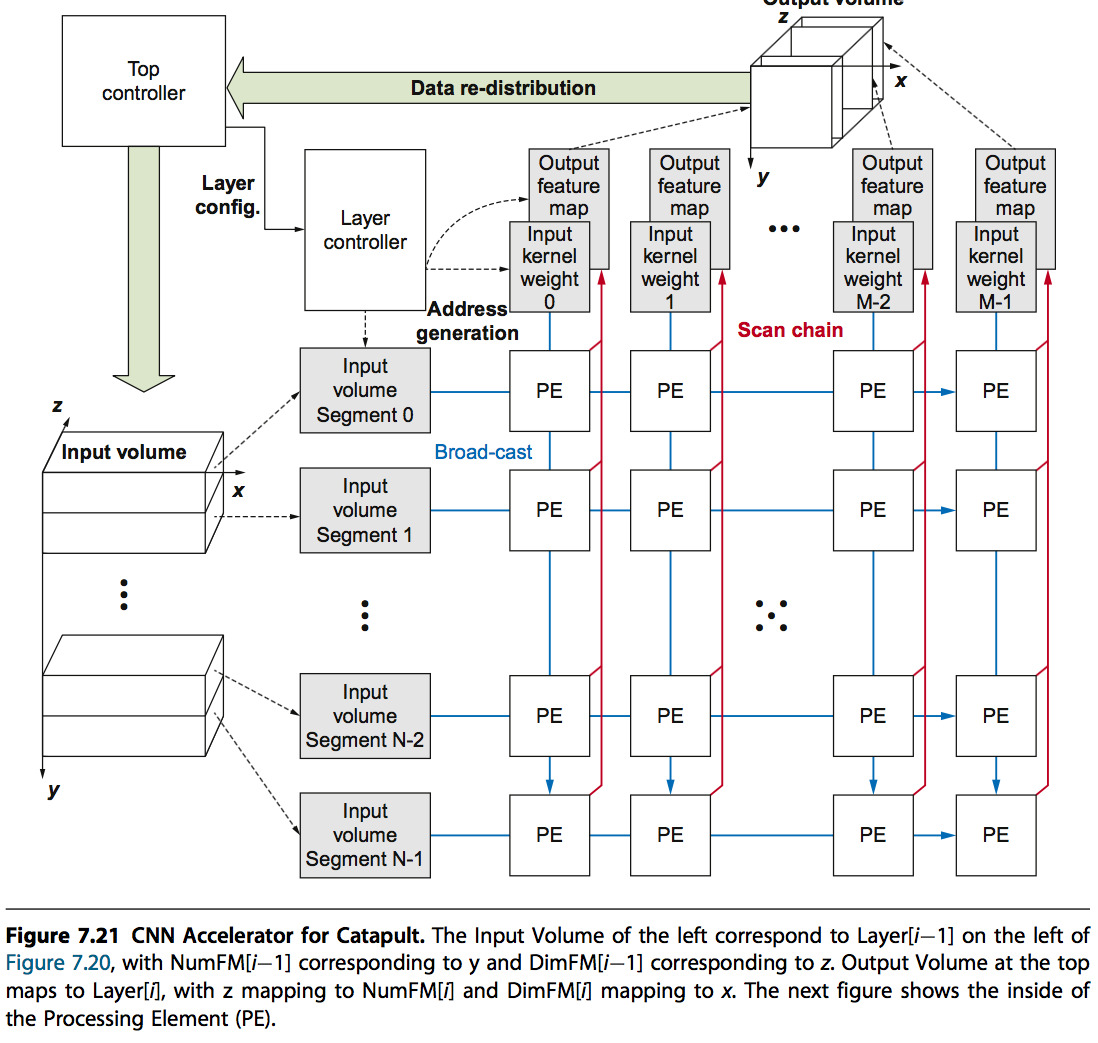
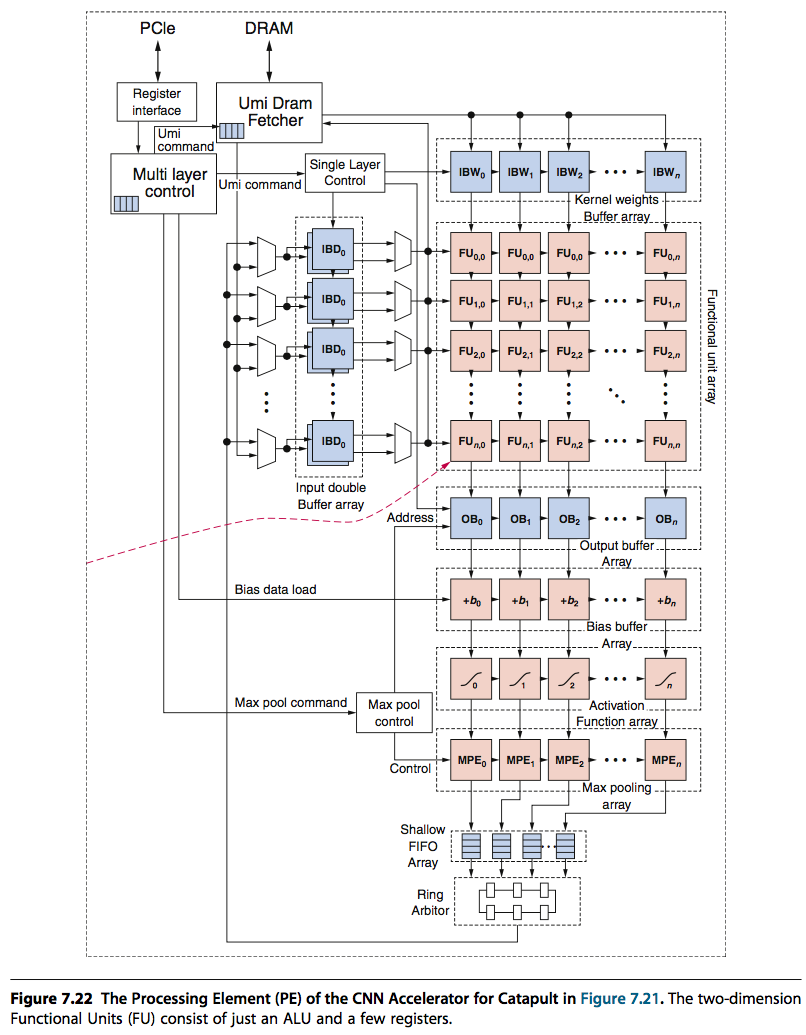
4. 应用一:CNN
先放上大图:
它具有如下特点:
- 在线动态配置,而不需要利用FPGA Tools重新编译
- 最小化内存访问,对CNN数据结构提供了高效的缓存
- 二维的PEs(Processing Elements)提供了很强大的扩展性
从下图也可以看出,catapult的PE也采用了脉动阵列的方式来提高计算密度。
5. 应用二:Search
一个软件的每个阶段都具有特殊性,因此都可以看作一个特殊都DSA可以解决都目标。Search就是这样都一个业务,它设计到都环节多,并且每个环节特性不完全一样,并且都需要较大都资源。一般来说,Search算法可以分为如下三大块内容(当然具体都会更复杂):
- Feature Extraction:从文档中提取特征,使用1块FPGA
- Free-Form Expressions:对特征进行处理,合并,使用2块FPGA
- Machine-Learned Scoring:对前面两个阶段的数据,利用机器学习方法,计算出代表文档的一个分值,使用3块FPGA
每个阶段都根据其特性进行了特殊化设计。
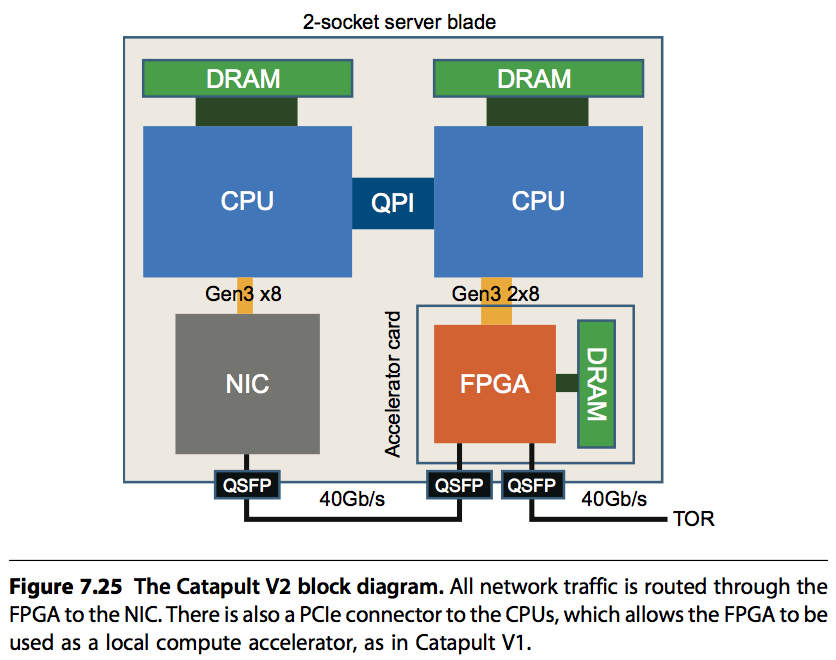
6. 改进
前面都设计有一些不足,最大问题是上面独立的网络不支持Ethernet/IP的处理,这样不能适用于网络加速这个场景,同时由于专有硬件线路会比较昂贵,因此FPGA网络被限制在48这个数量上,最后当出现问题时专有网络需要重新路由会对性能有影响。
因此catapult第二代做的最大改进就是将FPGA放置在CPU和网卡之间。既能支持Ethernet/IP加速网络,又能通过前面的方案加速计算。
同时还有三点相关的升级:
...
- 数据中心网络从10G升级到了40G
- 给FPGA增加一个rate limiter,避免FPGA应用霸占网络带宽
- 网络工程师用FPGA来加速网络

Domain Specific Architecture:TPU 发布于 April 22, 2018
1. 简介
- 用于Inference
- 有65536(256*256)8bit ALU Matrix Multiply Unit
- 大内存
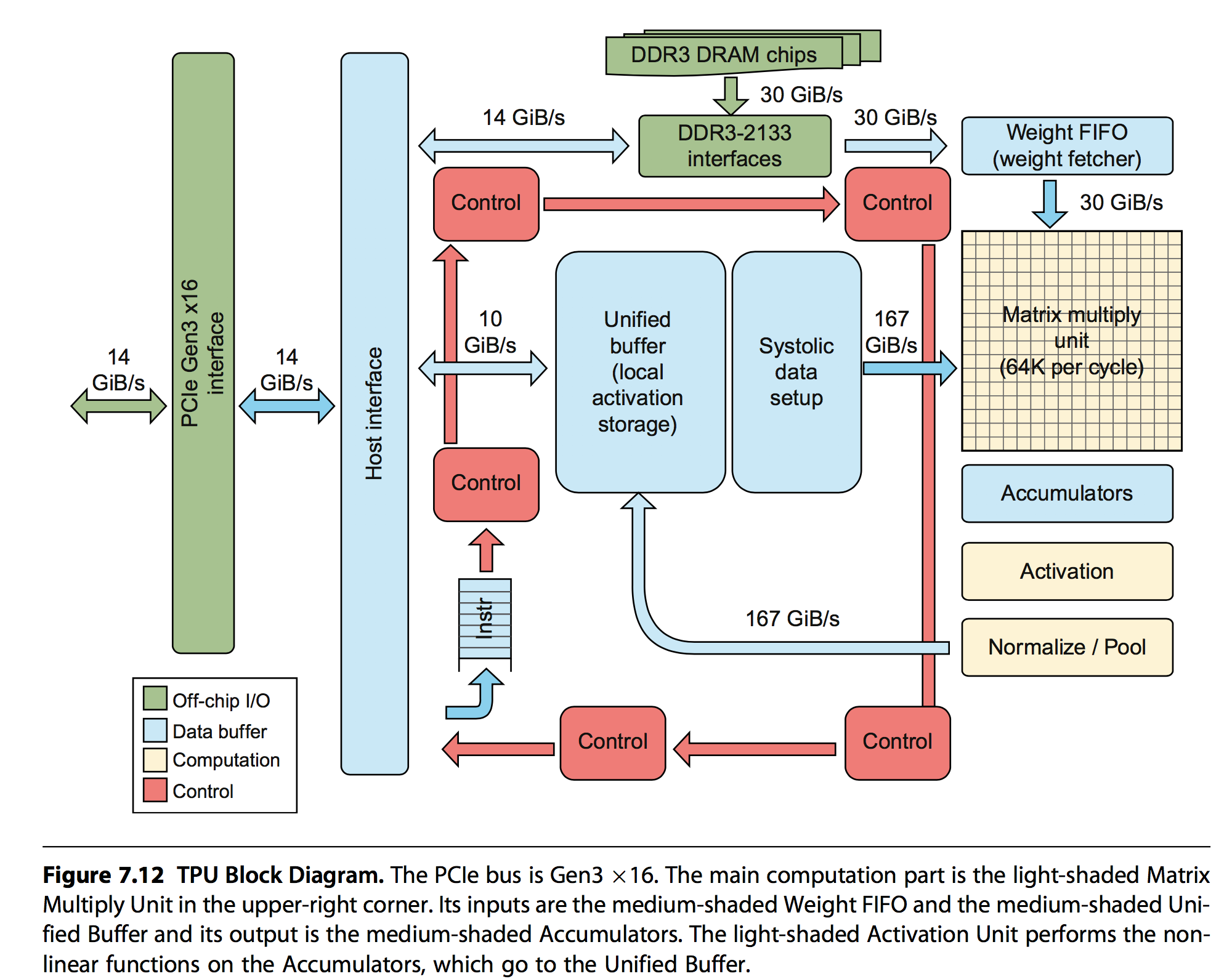
2. 架构
先摆出基本架构图:
几个主要组成部分是:
- Matrix Multiply Unit:执行8bit的矩阵乘加
- Accumulators:存储矩阵乘加输出的中间结果
- Activation:执行非线性激活函数
- Weight FIFO:从外部的Weight Memory中缓存权重信息
- Unified Buffer:从主机内存中读取中间结果
3. 主要操作
结合架构中的主要部件,主要有如下指令操作:
- Read_Host_Memory:从主机读取输入信息到Unified Buffer中
- Read_Weight:从Weight Memory中读取权重信息到Weight FIFO中
- MatrixMultiply/Convole:将Unified Buffer中的信息与Weight FIFO中的信息执行指定操作,结果存储到Accumulators中
- Activate:执行非线性激活函数,并将结果写回到Unified Buffer中
- Write_Host_Memory:将结果写回到主机内存中
TPU中的指令有12 bytes,其中3个bytes是Unified Buffer地址,2个byte是Acumulators地址,4个byte是length,剩下的是opcode和flags。
TPU的设计哲学就是保持MatrixMultiply处于繁忙的状态,最大化的发挥计算能力。和流水线的思路一致,将上述的操作都用专门的硬件来执行,同时在执行MatrixMultiply操作的时候,也并行的激发其他硬件的工作,这样就会将部分时间overlap掉,从而降低计算需要等待的时间。为了进一步提高并发行,Read_Weight的操作也会解耦,由于是专门硬件在处理,所以该操作可以在发送address,但是weigths从Memory中读取到之前就返回,MatrixMultiply通过专门的not-ready信号来判断数据是否准备好。
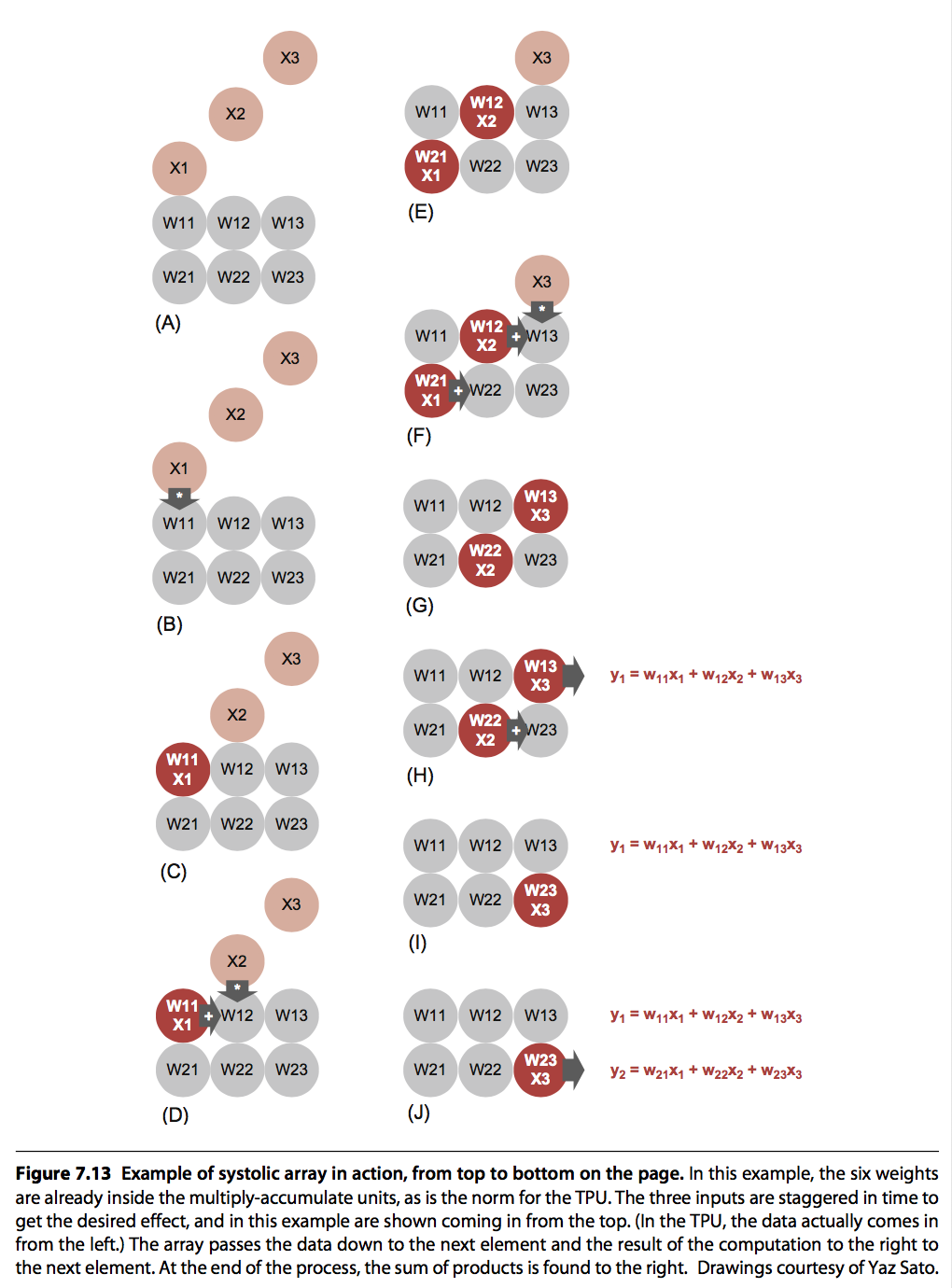
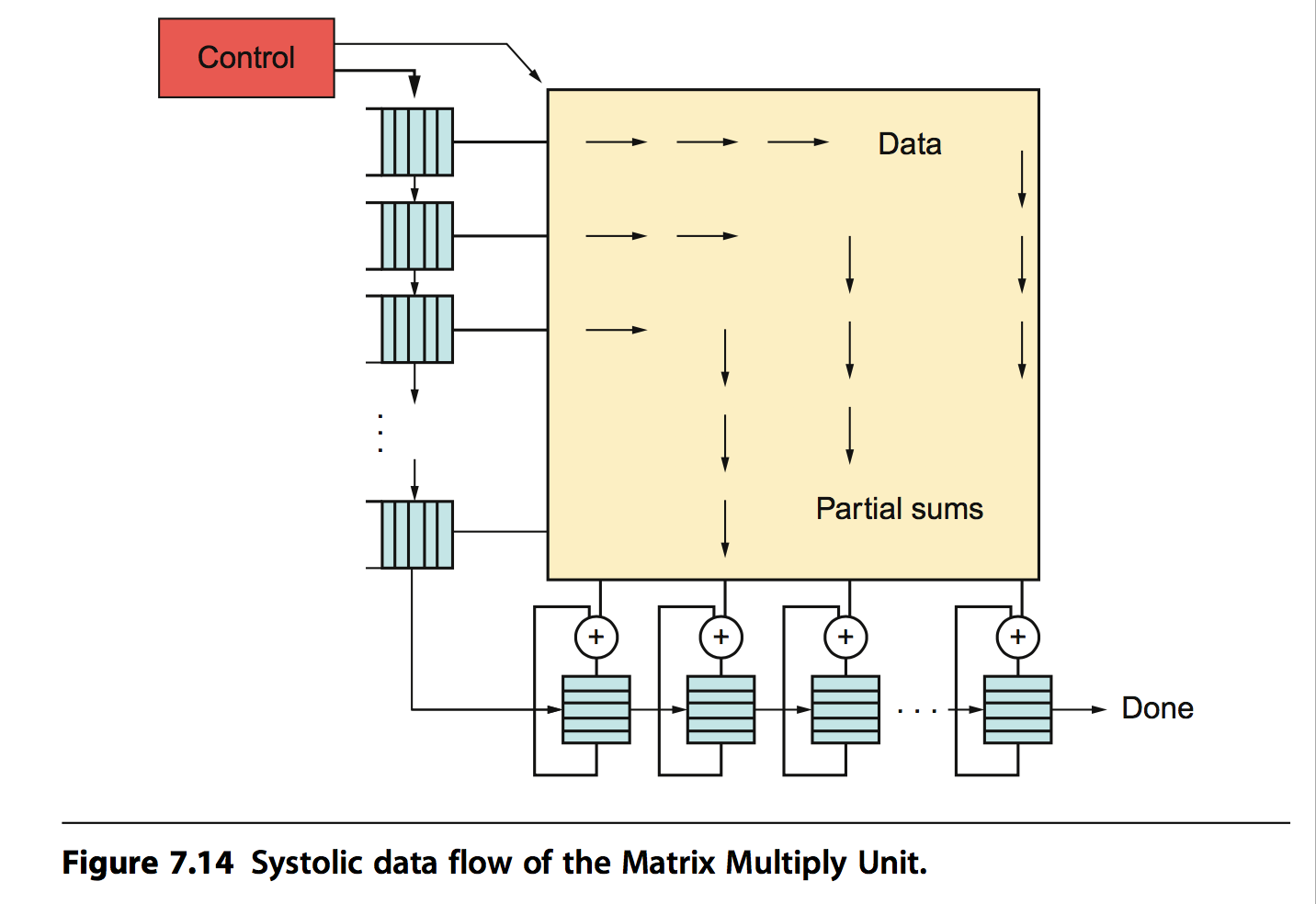
TPU中MatrixMultply应用的一个关键技术是:脉动阵列。它是结合矩阵运算这种特殊的场景而设计的专有硬件计算架构。脉动阵列是一个二纬计算单元的阵列(当然也存在更高纬度的),阵列中的每个cell利用相邻单元传递过来的参数和中间结果计算这一个cell的中间结果,数据依次传递,而不是重新从内存中读取,犹如波浪一般,脉动阵列因此得名。这种结构只需要读取一次内存数据,写入一次最终的结构到内存,因此计算非常高效。
TPU中脉动阵列的实现如下图所示:
4. 实现
硬件实现的一些基础信息如下:
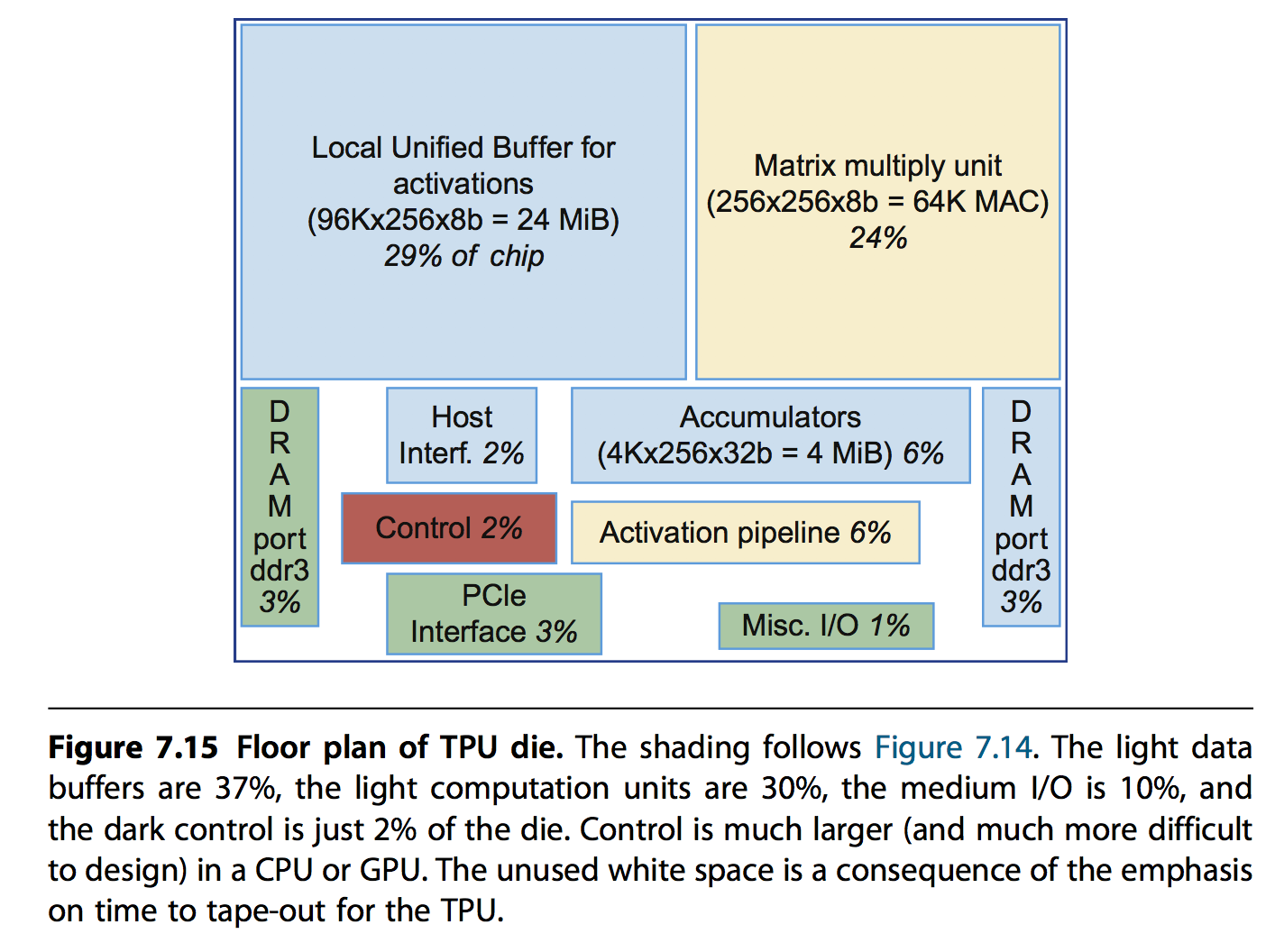
- 28nm,700MHz,芯片面积应该小于Intel Hashwell CPU(662mm*mm)
- Unified Buffer,24MiB,占了约芯片面积三分之一的空间
- 控制逻辑只占有2%的空间 也就是说计算密度非常大。框图如下:
配套软件上的实现信息如下:
- 基于TensorFlow,和GPU接口保持兼容
- Kernel Driver,用来管理内存和中断,非常稳定
- User Space Driver,包括模型编译,格式化数据到TPU的order,控制具体执行逻辑
- 每次计算一个layer,尽量hidder非关键操作
一些性能评估模型表明,TPU的几个关键组件影响性能的程度:
- Memory,影响非常明显,因此使用更快的内存很有必要
- Clock,提升效果不明显,这是因为很多时间都是在等待内存
- Matrix大小,反而有副作用,这是因为矩阵更大,一次计算时间会成幂数增长,比如一个600600的计算,在256256的MatrixMultiply中需要9个step,每次2us,总计18us,而在512512下,虽然只需要4个step,每次8us(22*2),但是总时间会变为32us
5. 评估
待补充
...
Domain Specific Architecture:Introduction 发布于 April 22, 2018
1. Introduction
硬件功耗极限没有像性能那样增长,因此当前为了提升硬件极限,则需要优化energe per operation。
如果按照以往的技术,更多核心可能能获得10%左右的性能的提升,但是要想性能进一步提升,则需要将arithmetic operations per instruction提升百倍,这就更需要专用处理器。
以后的系统,会有通用的处理来处理一些例如操作系统的通用任务,而专用处理器则完成他擅长的工作,比如某种计算。
以前一些架构的特性,比如cache,out-of-order等能很好等满足通用计算等需求,但是对于一些特殊等领域则会在silicon和energe上都有浪费,反而不使用这些通用特性能获得更大优势。比如vedio领域,数据往往很大,也基本上不重用,cache则完全是浪费。
DSA往往只针对系统的某个subset,而不是考虑支撑其整个系统。对于DSA研究来说,最大的两个问题是:
- 怎样平衡成本,因为NRE(nonrecur- ring engineering)和软件支持的成本是很高的,如果需求量小,得不偿失。FPGA是一个选择。
- 怎样将算法移植到硬件上,传统的C++开发和编译等组件不会发挥多少作用
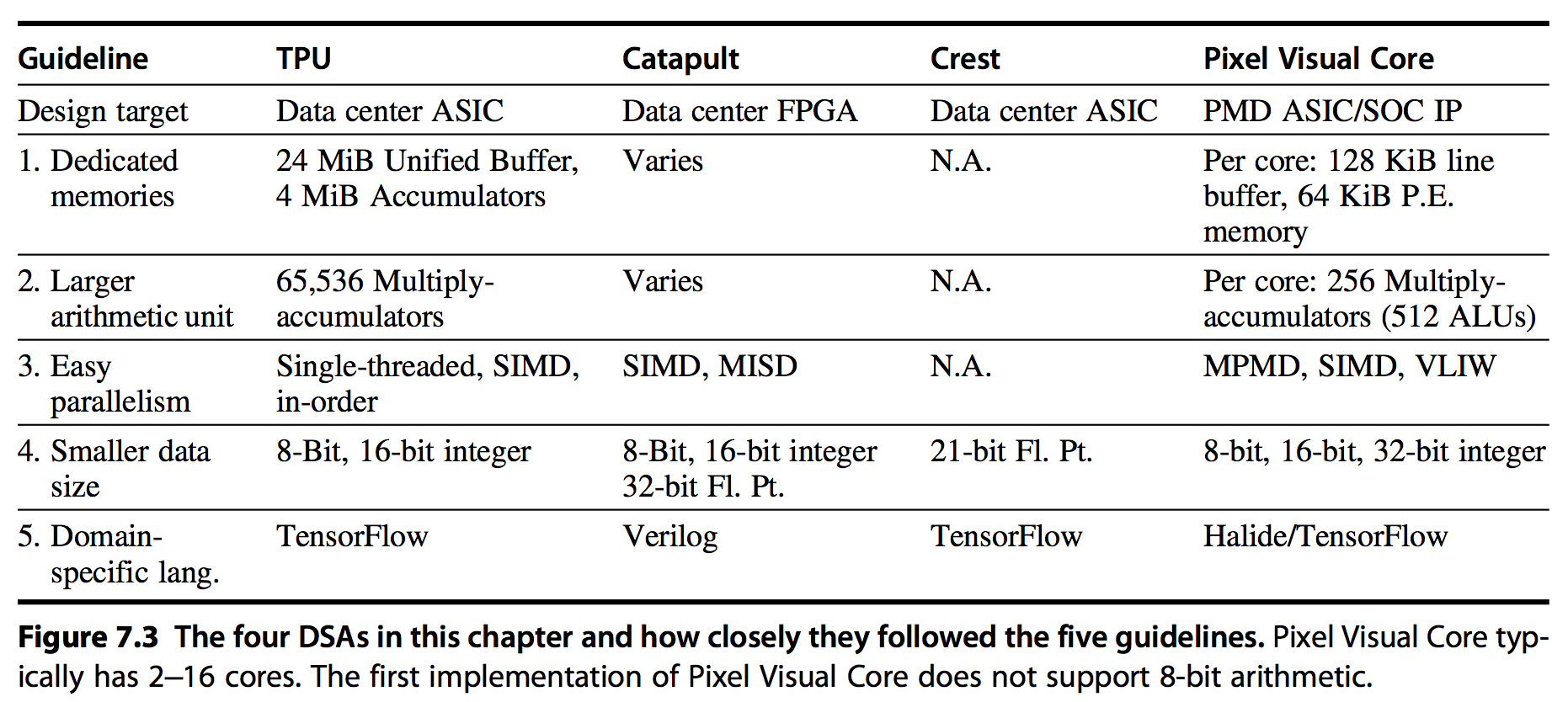
2. Guidelines for DSA
下述Guidelines有如下好处:
- 帮助增加area和energe等效率
- 尽量降低DSA的NRE成本
- 相比传统架构的优化,能更好的满足面向用户的latency需求
基于对处理问题的数据和执行的操作更理解,提出了如下5点Guidelines:
- 用专门设计的内存减少数据搬移的距离:a two-way set associative cache uses 2.5 times as much energy as an equivalent software-controlled scratchpad memory
- 将资源倾向更多的计算和更大的内存,而不是传统先进微架构为了满足摩尔定律的优化手段(out-of-order execu- tion, multithreading, multiprocessing, prefetching, address coalescing, etc)
- 使用符合domain的更简单的并行手段:For example, with respect to data-level parallelism, if SIMD works in the domain, it’s certainly easier for the programmer and the compiler writer than MIMD. Simi- larly, if VLIW can express the instruction-level parallelism for the domain, the design can be smaller and more energy-efficient than out-of-order execution.
- 减少data size,够用即可,可以提高内存利用率,也可以在相同chip area放更多计算units
- 使用domain-specifc的语言
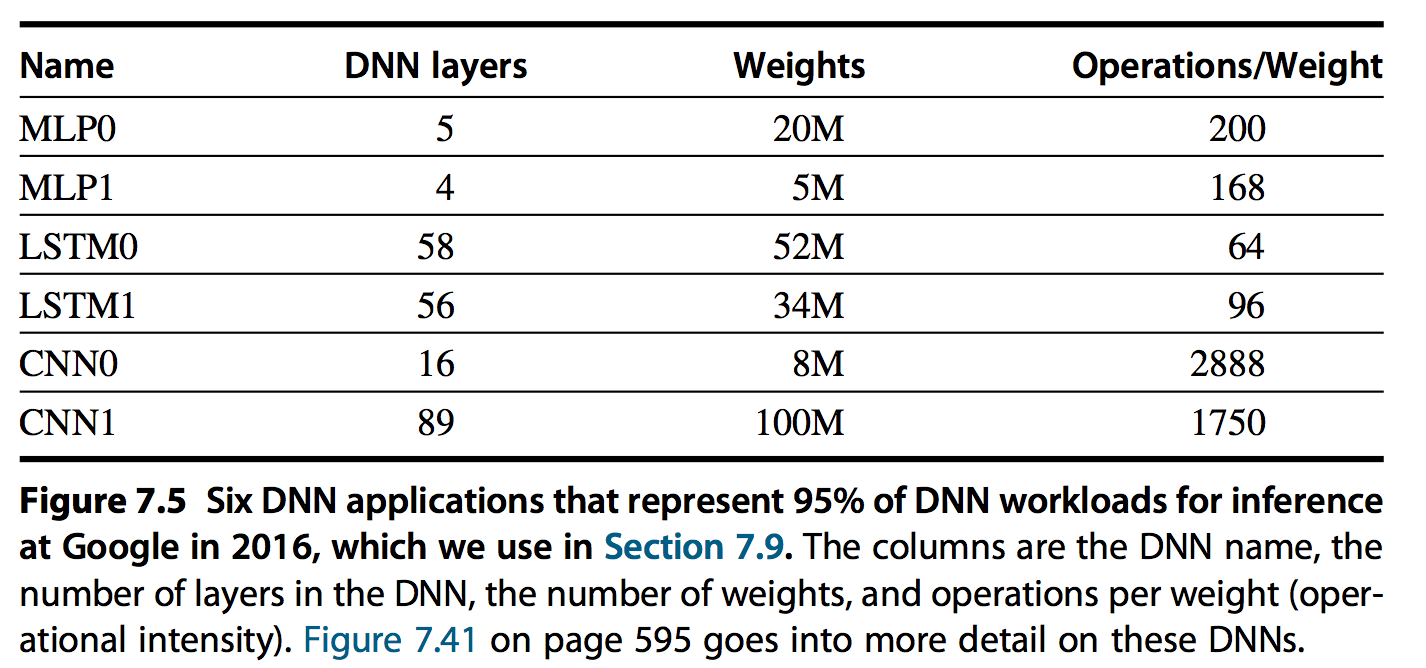
3. DNN简介
最常见的DNN信息如下:
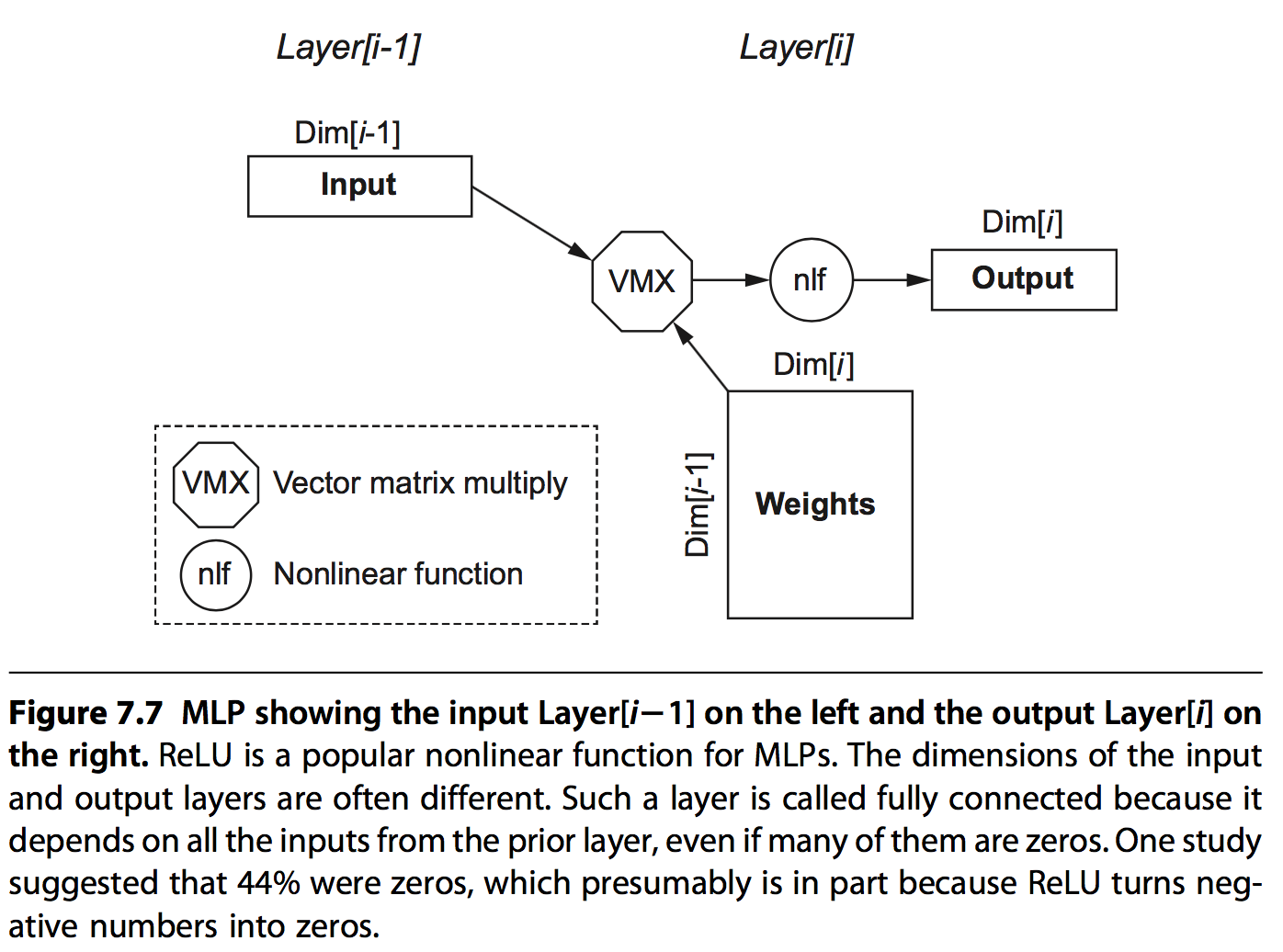
3.1 MLPs
MLPs是最原始的DNN,他的每一层都是上一层的输出和一组权重值矩阵相乘的结构。由于每个feature值都以来上一层的所有输出,所以这种方式称为全互联(fully connected)的方式。
它的主要结构图如下:
通过此结构,可以很容易的计算出每层网络的一些基本信息:
- Dim[i]: Dimension of the output vector, which is the number of neurons
- Dim[i 1]: Dimension of the input vector
- Number of weights: Dim[i 1] Dim[i]
- Operations: 2 Number of weights
- Operations/Weight: 2
Operations/Weight只有2,也就是operation intensity 只有2,根据roofline模型可知,此模型很难有很高的performance。
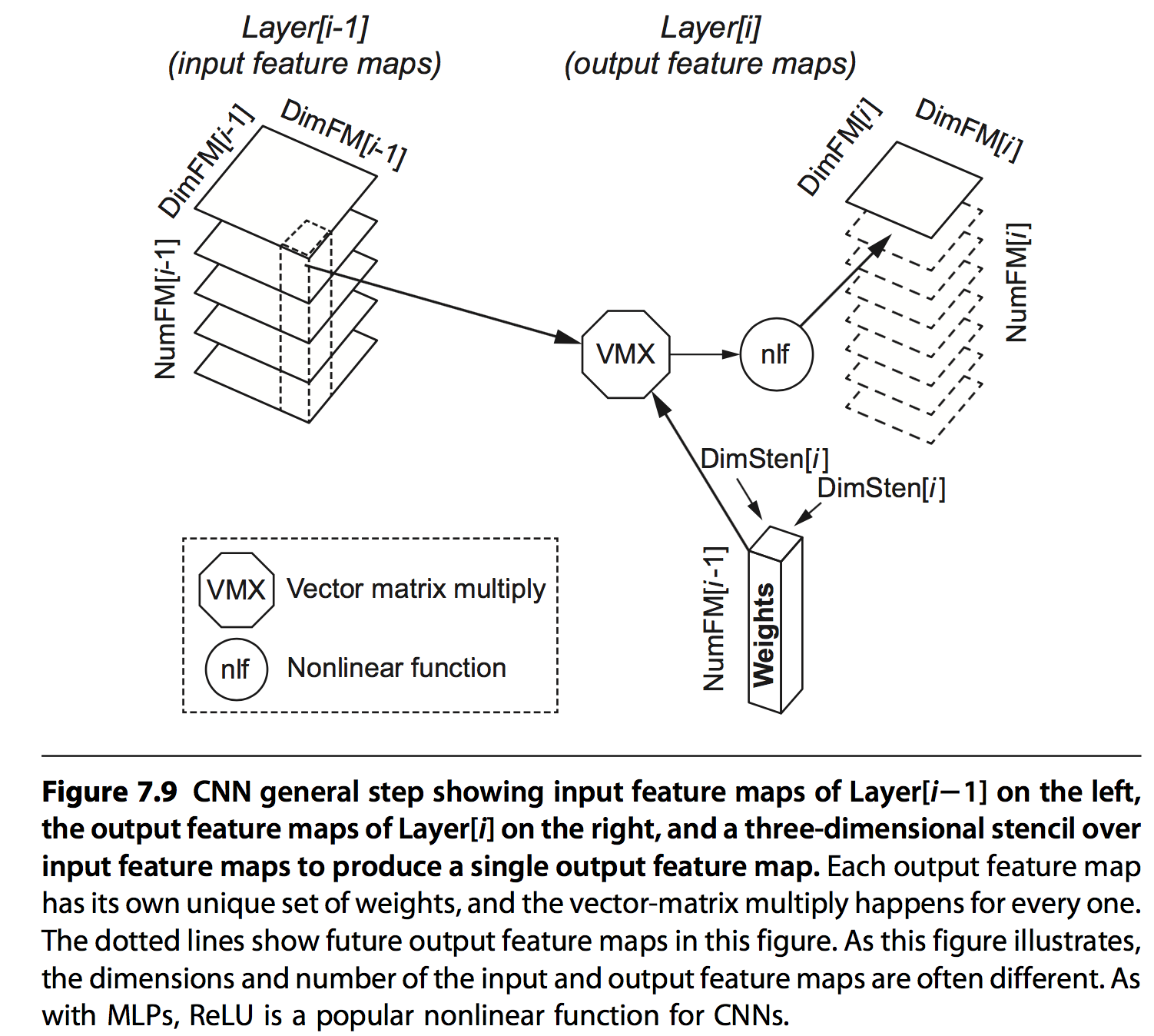
3.2 Convolutional Neural Network
CNN是另外一种形式,每个feature值是前一层输出的部分值与权重乘加的结果,基于两点:
- 一些场景下(比如图片),相邻的数据往往具有相关性
- 每一层layer都会提高对象(比如图片)的抽象级别,从线到图形到鼻子到类别等
其具体结构如下:
每层网络的基本信息:
3.3 Recurrent Neural Network
RNN在一些上下文关联的场景特别有用,比如语音识别。使用的方法就是给序列化输入建模时增加状态,也就是说模型会记录之前的一些信息。
LSTM是当前最流行的算法,通过long-term memory记录长期信息,short-term memory记录上一次的信息,并通过相应的weights以及gates来作用到输出。
weights是用来做矩阵求和的,gates则是用来确定哪些信息能作用到输出或者memory中:
- input gates,output gates,用来筛选输入输出;
- forget gates,用来筛选哪些作用于long-term memory
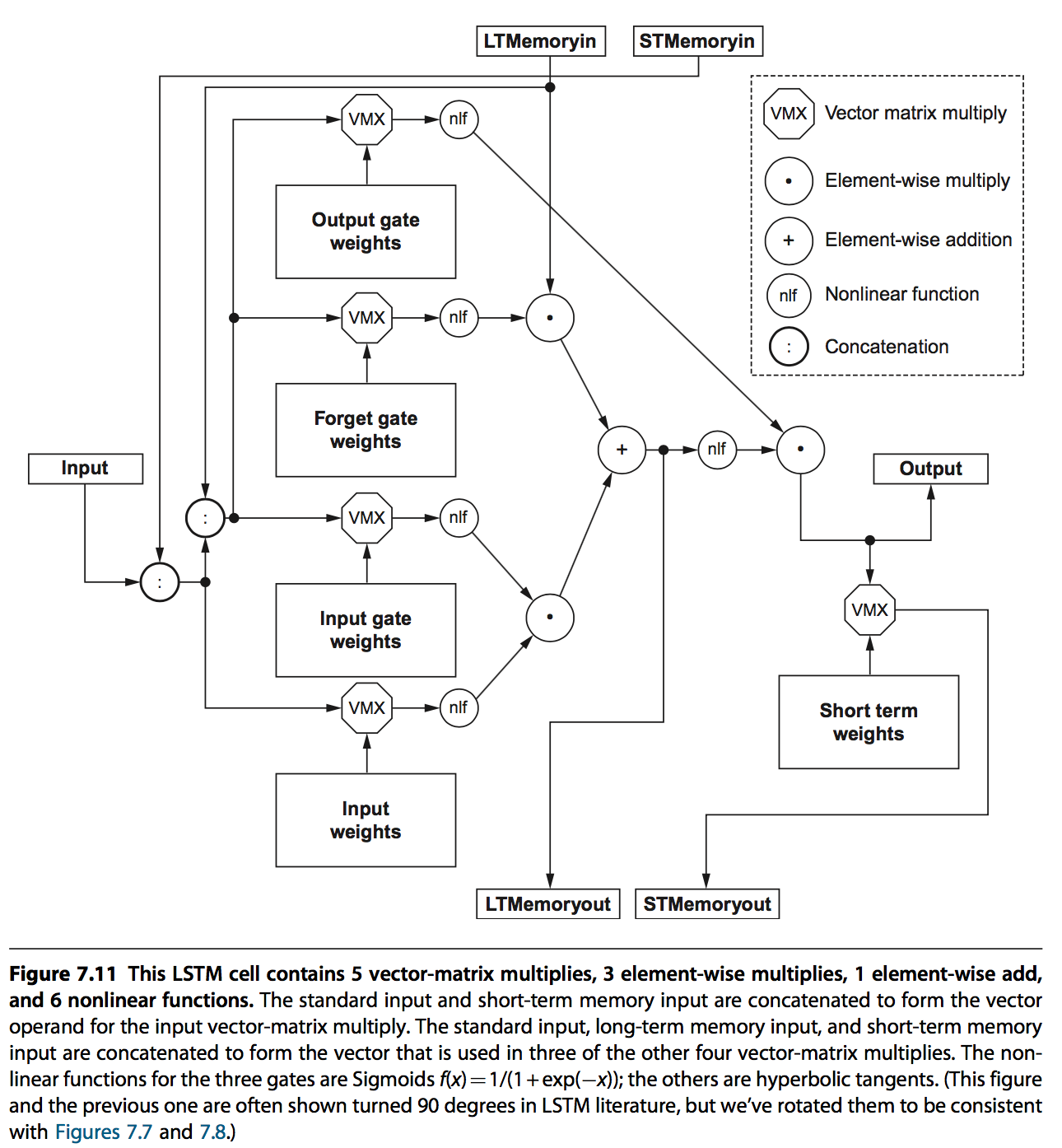
每一个cell的结构如下:
LSTM相关的一些信息如下:
...





使用opengrok高效率阅读源码 发布于 April 20, 2018
1. 环境安装
1.1 安装JDK
从如下地址下载JDK安装包:http://www.oracle.com/technetwork/java/javase/downloads/jdk10-downloads-4416644.html
安装完成后,通过
java --version命令查看是否安装成功:java 10.0.1 2018-04-17 Java(TM) SE Runtime Environment 18.3 (build 10.0.1+10) Java HotSpot(TM) 64-Bit Server VM 18.3 (build 10.0.1+10, mixed mode)
1.2 安装Tomcat
Tomcat可以通过如下命令安装:
brew install tomcat1.3 设置环境变量并验证Tomcat
在~/.bashrc或者~/.bash_profile中添加如下环境变量 a) 设置JAVA环境:
export JAVA_HOME=$(/usr/libexec/java_home)b)设置Tomcat环境:export PATH=$PATH:/usr/local/Cellar/tomcat/9.0.7/bin/c)设置OpenGrok的Tomcat路径:export OPENGROK_TOMCAT_BASE=/usr/local/Cellar/tomcat/9.0.7/libexec/启动tomcat:
catalina run,看到如下页面表示环境安装成功:1.4 安装Ctags
MacOS下可以用如下命令安装ctags:
brew install ctags1.4 安装OpenGrok
从如下地址下载OpenGrok包:https://github.com/oracle/opengrok/releases
然后解压到/usr/local目录下,并进入目录
cd /usr/local/opengrok-0.12.1.5/bin运行./OpenGrok deplo。通过
localhost:8080/source即可看到如下页面,表示环境均安装成功:2. 源码管理
给需要管理的源码建索引:
./OpenGrok index ~/Documents/ProjectCode/Github/src/,其中最后的绝对路径需要替换成自己项目路径。完成操作后,即可开始遍历源码:
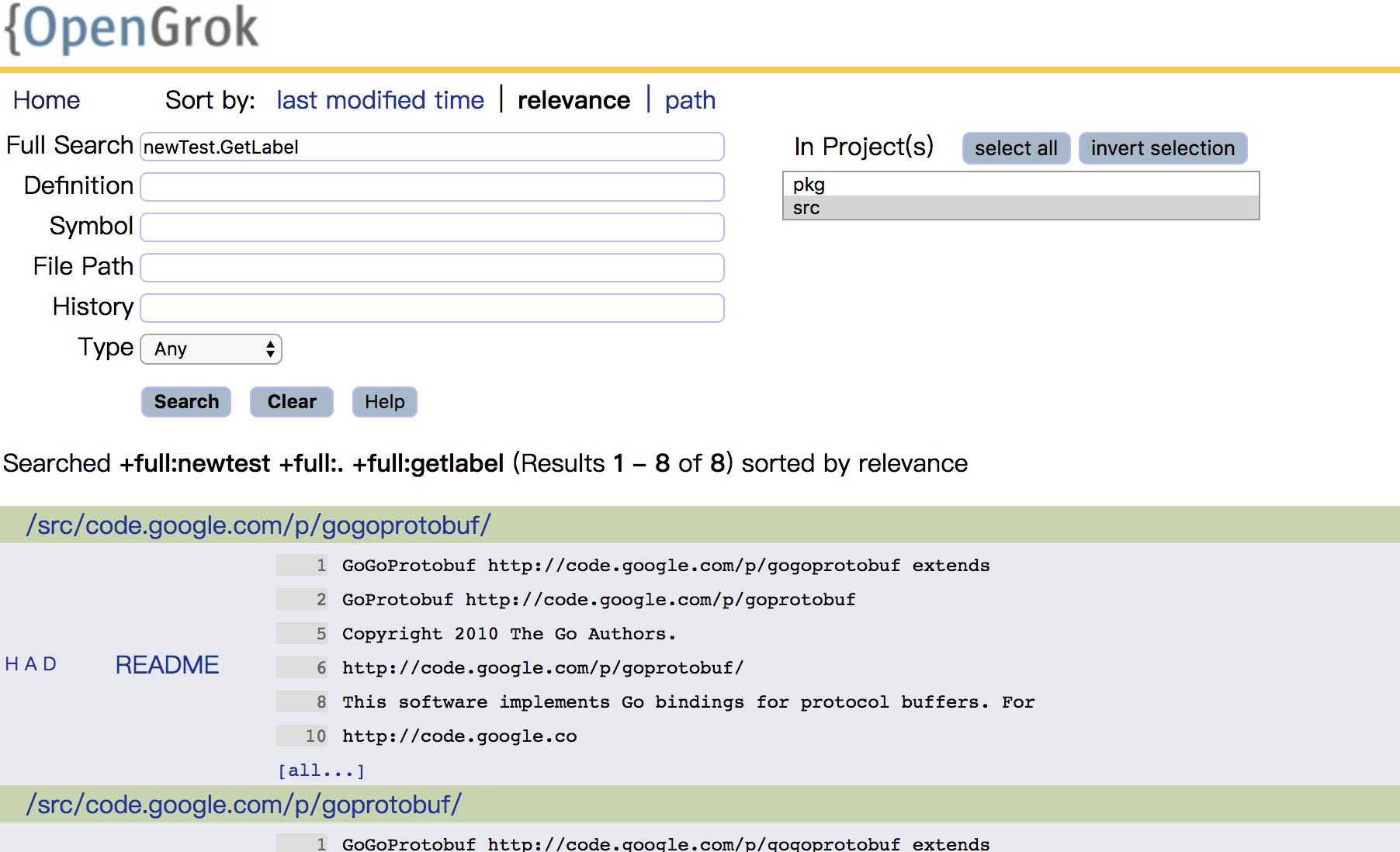
搜索具体的函数或者变量:
...
- 标签:
- OpenGrok 1
etcd源码学习(一):启动流程 发布于 March 31, 2018
源码结构
【TODO:源代码层次结构】
etcd
etcd的入口main函数定义在etcdmain/main.go中,在其中主要工作如下:
- 检测平台支持情况:checkSupportArch()
- 分析rpc相关的参数
- 启动etcd以及按照rpc设置启动proxy
然后调用etcdmain/etcd.go中的startEtcdOrProxyV2(),其主要就是解析config的工作,etcd是自身定义了一个较为复杂的config struct:
type config struct { ec embed.Config cp configProxy cf configFlags configFile string printVersion bool ignored []string }通过上面各config成员实现非常丰富的configure功能。后续专门分析其config实现,以及可借鉴之处。
完成解析后,则调用startEtcd()和startProxy()分别启动etcd主逻辑,以及proxy。
startEtcd调用embed/etcd.go中的StartEtcd,其主要流程是:
至此etcd就启动了,其中有两个非常重要的功能,
- startPeerListeners(),创建peerListeners
- startClientListeners(),创建clientListeners
- e.servePeers(),启动peerListeners协程处理请求
- e.serveClients(),启动clientListeners协程处理请求
- e.Server.Start(),再提供服务前做一些必要的初始化,最终会在一个goroutine中运行raft相关操作
s.run()- s.run(),raft相关的操作
PeerListeners
peerListener定义如下:
type peerListener struct { net.Listener serve func() error close func(context.Context) error }
- net.Listener,调用Go基础库监听请求
- serve,接收到请求后具体的处理逻辑
- close,监听关闭的逻辑
startPeerListeners()定义在embed/etcd.go中,主要逻辑:
- 如果有设置,验证peer cert
- 根据cfg.LPUrls个数,申请peerListener对象
- 通过rafthttp.NewListener()设置每个peerListener的net.Listener对象
rafthttp
etcd的分布式协议采用的是raft,它实现的非常高效,如果自己的项目中需要在Go语言中利用raft协议,可以直接借用。对于raft协议,可以参考。 【TODO:etcd里面rafthttp的实现】
ClientListeners
clientListener定义如下:
type serveCtx struct { l net.Listener addr string secure bool insecure bool ctx context.Context cancel context.CancelFunc userHandlers map[string]http.Handler serviceRegister func(*grpc.Server) serversC chan *servers }它的启动逻辑比peerListener要简单,就是根据config配置的接口启动相应的net.listener。
- 如果fd数量有限制,调用transport.LimitListener()
- 如果是tcp协议,调用transport.NewKeepAliveListener()设置链接
- 根据config,设置userHandlers、registerPprof、registerTrace
这样就等着client请求一些操作了。
etcdctl
【TODO:各中命令实现】
...
Learning Package In Etcd 发布于 March 28, 2018
...
- runtime
- log
- capnslog
- cobra:
- google.golang.org/grpc:Go下的rpc应用
- github.com/coreos/go-systemd:Go环境下利用systemd
- embed/config.go:etcd提供的专用的配置接口
- pkg/fileutil:etcd封装的file相关操作接口
- 标签:
浅谈硬件体系结构中的并行 发布于 March 24, 2018
1. 指令并行
2. 数据并行
3. 线程并行
4. Warehouse-Scale
...
Go语言快速入门(三):并发编程 发布于 March 24, 2018
躁动起来,Go自所以成为Go,就是因为它的主要特性并发的关键字是“go”。通过一个关键字go就可以让一个函数以并发的形式运行起来,而不是调用一系列pthread接口,还不知道怎么搞。
为什么要并发编程,这就不多说了。多进程,多线程,协程,异步IO,都是为了解决程序的运行效率,为了充分利用现在体系结构中的并行特性。关于硬件上的并行,在文章浅谈硬件体系结构中的并行中再介绍介绍(当前还未完成)。
Go实现并发非常简单,在函数调用起来使用go关键字即可。
...
- 标签:
- Go 3
- Kubernets 3
Go语言快速入门(二):面向对象 发布于 March 23, 2018
摘录一段《Go语言编程》中的介绍:
Go语言的主要设计者之一 布 派 (Rob Pike) 经说过,如果只能选择一个Go语言的特 性 到其他语言中,他会选择接口。 接口在Go语言有着 关重要的地位。如果说goroutine和channel 是支 起Go语言的并发模型 的基 ,让Go语言在如 集群化与多核化的时代成为一道极为 的风景,那么接口是Go语言 整个类型系统的基 ,让Go语言在基础编程哲学的 上达到前所未有的高度。 Go语言在编程哲学上是变革派,而不是改良派。这不是因为Go语言有goroutine和channel, 而更重要的是因为Go语言的类型系统,更是因为Go语言的接口。Go语言的编程哲学因为有接口 而趋近完 。Go面向对象的核心就是接口,interface。
...
- 标签:
- Go 3
- Kubernets 3
Go语言快速入门(一):基础篇 发布于 March 21, 2018
Go是一门比较新的语言,是由一群牛人在Google推出的,这些牛人大多来自贝尔实验室的Plan 9操作系统项目和Limbo语言设计项目,因此大多认为Go的前身就是Limbo。同时这些牛人中有C语言的设计者Ken Thompson,因此Go的设计里面也包含了一些C的思想或者去解决一些C语言上效率的问题。
它的主要语言特性有:
- 自动的垃圾回收,针对内存泄漏和野指针
- 原生支持一些复杂的类型,字典、数组切片(动态数组)
- 匿名函数和闭包
- 有限的类型和借口
- 多函数返回值
- 统一的错误处理机制,defer、panic、recove
- 原生支持并发编程
- 反射
- 语言交互性好
果然是一门“现代”语言,一门“更强的C语言”。
这个系列的几篇博客,主要就是记录下Go的基础要点,以及一些学习过程中的思考,也希望对有缘的人有所帮助。
- 基础,就是和其他语言有什么不同,主要是C和C++
- 面向对象,简单必要的面向对象设计
- 并行编程,这是Go语言的优势所在
- 高级特性,一些特性或者装逼情况下可用
本文中的内容绝大多数都参考了大牛许式伟的《Go语言编程》,所以也相当于是学习笔记了。
...
- 标签:
- Go 3
- Kubernets 3
网站增加百度&Google支持 发布于 March 20, 2018
增加一些辅助功能,能让我们的博客更有价值。比如,
- 百度或者google的搜录能带来更多的流量
- 百度或者google的统计能告诉我们博客的压力
因此本文介绍怎样在博客中增加这些支持。
...
- 标签:
- blog 2
Study BenchIP, a Benchmark for AI Hardware 发布于 March 18, 2018
Benchmark对于评估不同系统优劣,以及系统的优化(包括软件和硬件的优化)都大有裨益。当前存在的问题:
- 当前的benchmark对于智能芯片来说,缺点是non-diversity和nonrepresentativeness,导致不可用
- 缺少一套标准的benchmarking methodology
从这两个角度出发,提出了BenchIP,一个benchmark套件以及benchmark的思路。BenchIP主要分为两块:
- microbenchmark,单层网络下的典型操作,主要用于评估系统瓶颈以及系统可优化点
- macrobenchmark,使用最领先的网络,测试不同平台在实际系统下的性能
BenchIP被设计成可用来评估不同的平台,CPU,GPUs,和其他加速器,这也是我们自己定义或者借鉴benchmark需要考虑的问题。
...
- 标签:
- benchmark 1
利用jekyll搭建简单的Blog 发布于 March 18, 2018
爱分享的人总是喜欢记录下自己的一些想法,一是便于自己以后总结抽象,二也是为了给遇到相同问题或者考虑相同事情的人一些建议。
记录自己想法的方法很对,但对于程序员来说,不少都喜欢借助Github的Page来建立专属页面,既不会自己利用wordpress搭建博客那么复杂,又不会像一般都博客网站那样单一,可以自己定制。
本Blog也是利用Github的Page来搭建的。
...
- 标签:
- blog 2
深入理解cache(一) 发布于 June 4, 2017
在《深入理解CACHE-1》中有简单介绍CACHE的Hierarchies,里面介绍了经典的inclusive的基本操作。除了inclusive模式外,exclusive也是一种重要的Cache Hierarchies,两者也被多次拿出来比较,各有优劣。本文旨在结合Cache Hierarchies,继续深入了解下CACHE的操作,以及对性能的影响。
...
- 标签:
- cache 2
指令是怎样执行的 发布于 June 3, 2017
一条指令执行的过程。
...
- 标签:
- cpu 4
深入理解cache(一) 发布于 June 3, 2017
cache是万金油。无论是硬件设计,模块开发,还是架构设计,cache都是一个解决性能问题,加速业务性能的、简单直接的方案。为了更深入的理解cache,需要对cache的基本结构,cache的分析思想都有深入的理解。本文也就是对最近的学习做一些总结。
...
- 标签:
- cache 2